Pseudonymisation RGPD : Maîtrisez les techniques et l'IA
Pseudonymisation RGPD : Maîtrisez les techniques et l'IA
Maîtrisez la pseudonymisation RGPD. Explorez ses techniques, la distinction avec l'anonymisation et son usage avec les IA. Restez conforme.
Parler de ce sujet avec Webotit
Le chiffre qui devrait alerter n'est pas le niveau de sensibilisation au RGPD. C'est l'écart entre l'intention et l'exécution. Une étude de l'EDPB a révélé que si 68 % des entreprises françaises considèrent la pseudonymisation comme une mesure de conformité clé, seulement 34 % appliquent les conditions strictes de stockage séparé des clés et des mesures techniques requises par l'article 4(5) du RGPD (étude EDPB 2022). C'est là que se crée le vrai risque.
Dans une entreprise qui déploie des agents IA, des chatbots ou des workflows de service client automatisés, ce décalage devient critique. Les flux de données sont continus. Les identifiants circulent entre CRM, outils de ticketing, bases documentaires, moteurs de recherche interne et modèles de LLM. Une pseudonymisation RGPD mal conçue ne ralentit pas seulement la conformité. Elle fragilise tout le dispositif opérationnel.
Le sujet dépasse largement la technique. Il touche la gouvernance, l'architecture, les rôles d'accès, la traçabilité et la manière d'intégrer la privacy by design dans les opérations. C'est particulièrement vrai dans les secteurs réglementés, mais aussi dans des activités plus exposées à la donnée client comme l'immobilier, où des ressources concrètes existent pour assurer la conformité des agences immobilières avec une approche métier. Même logique pour les organisations qui automatisent la relation client et doivent penser la protection des données dès la conception de leurs parcours IA et conversationnels, pas après coup, y compris lorsqu'elles évaluent des solutions d'automatisation de la relation client.
Introduction Pourquoi la Pseudonymisation Est Stratégique
La pseudonymisation RGPD est souvent traitée comme une ligne dans une politique de sécurité. En pratique, c'est un choix d'architecture. Et ce choix détermine si une entreprise peut industrialiser l'IA sans exposer inutilement ses clients, ses salariés ou ses partenaires.
Le point de départ est juridique, mais l'enjeu est business. L'article 4(5) du RGPD encadre une mécanique précise. Les données ne doivent plus pouvoir être attribuées à une personne sans information supplémentaire, et cette information doit être conservée séparément avec des mesures techniques et organisationnelles strictes. Tant que cette discipline n'est pas tenue, l'entreprise ne bénéficie pas de la réduction de risque qu'elle croit avoir mise en place.
Le coût réel d'une mauvaise exécution
Dans les projets IA, le problème n'est presque jamais l'absence totale de protection. Le problème est la protection incomplète. Une équipe masque un nom dans l'interface, mais laisse l'e-mail dans les logs. Un chatbot remplace l'identité côté front, mais le transcript complet part dans un outil d'analytics. Un agent IA traite un alias, mais l'identifiant CRM est encore disponible dans les métadonnées.
Règle de direction: si la clé, la table de correspondance ou les métadonnées circulent dans le même périmètre que les données pseudonymisées, vous n'avez pas une pseudonymisation robuste. Vous avez un faux sentiment de sécurité.
Pourquoi le sujet est devenu central avec l'IA
Les environnements conversationnels sont plus exigeants que les traitements batch classiques. Les données y transitent en temps réel, sont enrichies, résumées, classifiées, routées et parfois réinjectées dans d'autres systèmes. C'est pour cela qu'une stratégie de pseudonymisation RGPD doit être pensée pour des flux vivants, pas pour un simple export ponctuel.
La bonne nouvelle, c'est qu'une fois bien conçue, elle devient un accélérateur. Elle permet de faire travailler des agents IA sur des données utiles sans exposer inutilement les identités. Elle réduit la surface de risque. Elle simplifie les discussions avec les équipes sécurité, conformité et achats. Et elle rend le passage à l'échelle beaucoup plus crédible.
Pseudonymisation vs Anonymisation La Distinction Cruciale
La confusion entre pseudonymisation et anonymisation coûte cher. Elle crée des décisions techniques fausses, des analyses de risque incomplètes et des contrats mal calibrés avec les sous-traitants.
La façon la plus simple d'expliquer la différence est la suivante. La pseudonymisation revient à remplacer “Jean Dupont” par “Client 48327”, tout en gardant une table de correspondance protégée ailleurs. L'anonymisation, elle, supprime toute possibilité réaliste de revenir à Jean Dupont. Dans un cas, on peut retrouver la personne avec une information supplémentaire. Dans l'autre, non.
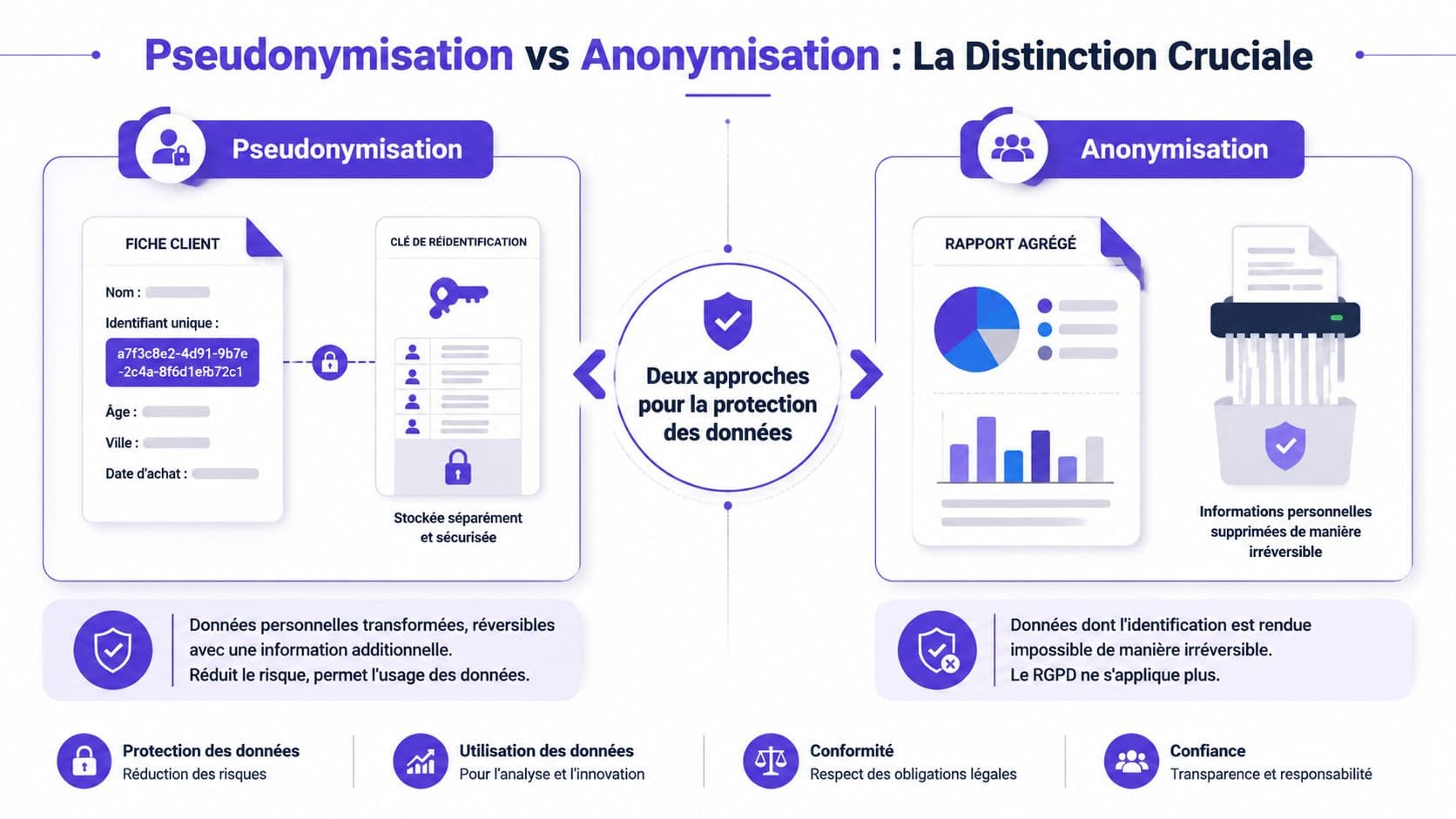
Le point juridique qui change tout
La pseudonymisation est définie par l'Article 4(5) du RGPD comme un traitement où les données ne peuvent plus être attribuées à une personne sans informations supplémentaires, qui doivent être conservées séparément. Contrairement à l'anonymisation, les données pseudonymisées restent des données personnelles (définition juridique détaillée).
Pour un dirigeant, la conséquence est directe. Si vous pseudonymisez, vous restez dans le champ du RGPD. Il faut donc maintenir base légale, limitation des finalités, durée de conservation, droits des personnes, sécurité, registre et gouvernance. Beaucoup d'équipes techniques pensent avoir “sorti” la donnée du périmètre réglementaire alors qu'elles ont seulement réduit sa lisibilité immédiate.
Cela change aussi la conception d'un dispositif conversationnel. Un chatbot de relation client peut fonctionner sur des alias ou des identifiants indirects, mais l'entreprise conserve l'obligation de maîtriser la chaîne complète de traitement.
Comparatif Pseudonymisation vs. Anonymisation
| Critère | Pseudonymisation | Anonymisation |
|---|---|---|
| Statut légal | Reste une donnée personnelle | Sort du champ du RGPD si l'identification est rendue impossible de manière irréversible |
| Réversibilité | Oui, via une information supplémentaire séparée | Non |
| Gestion des clés | Centrale | Pas de clé de retour à protéger |
| Risque de réidentification | Réduit, mais résiduel | Doit être matériellement irréaliste |
| Cas d'usage typiques | Service client, IA, analytics opérationnel, santé, banque | Statistiques agrégées, publication ouverte, partage sans besoin de retour à l'individu |
| Effet sur les droits RGPD | Les obligations restent | Les obligations ne s'appliquent plus si l'anonymisation est réelle |
Une donnée pseudonymisée n'est pas une donnée “presque anonyme”. C'est une donnée personnelle mieux protégée.
L'erreur la plus fréquente consiste à confondre masquage visuel et pseudonymisation. Remplacer “Jean Dupont” par “Jean D***” dans un écran n'apporte pas le niveau de protection attendu. Si l'utilisateur, l'administrateur ou le système peuvent encore rattacher facilement l'information à une personne, vous êtes loin du standard requis.
Implications Juridiques et Gestion des Risques Résiduels
Le point qui fait échouer beaucoup de projets n'est pas la connaissance du principe de pseudonymisation. C'est son exécution. Dans un environnement IA, surtout avec des agents et des chatbots qui ingèrent, reformulent, journalisent et transmettent des données en continu, le risque naît rarement d'un défaut théorique. Il vient d'un flux mal maîtrisé entre le prompt, les logs, les outils tiers, les exports et la table de correspondance.
Sur le plan juridique, la pseudonymisation améliore la position de l'entreprise. Elle réduit l'exposition en cas d'incident, soutient l'application du principe de minimisation et peut peser favorablement dans l'analyse des mesures de sécurité prévues par l'article 32 du RGPD. Elle ne fait pas sortir les données du champ du RGPD. Pour un comité de direction, la conséquence est simple. Les obligations restent là, mais le niveau de risque, lui, peut être mieux contenu si l'architecture est cohérente.
La clé de réidentification est le vrai point de rupture
Le risque résiduel se concentre sur un actif précis. L'information supplémentaire qui permet de rattacher un alias à une personne réelle. Si cette information est trop accessible, mal journalisée ou stockée dans le même périmètre opérationnel que les données pseudonymisées, la protection perd une grande partie de sa valeur.
C'est là que l'écart entre "savoir" et "faire" apparaît clairement. Beaucoup d'entreprises financent des outils de chiffrement, de tokenisation ou de contrôle d'accès. Puis elles laissent une équipe support, un administrateur transverse ou un fournisseur accéder indirectement à la réidentification pour gagner du temps en production. Le compromis paraît mineur. En audit, en contentieux ou après une violation, il devient très coûteux.
Trois défaillances reviennent régulièrement :
- Accès trop large à la table de correspondance. Des équipes métiers ou techniques y accèdent hors procédure formelle.
- Séparation incomplète. Les données pseudonymisées, les secrets, les journaux et les consoles d'administration restent dans le même environnement.
- Réidentification sans preuve. L'entreprise ne peut pas démontrer qui a demandé l'accès, sur quelle base, ni si la finalité était légitime.
Une pseudonymisation sans contrôle strict de la réidentification réduit peu le risque réel.
Dans les systèmes d'IA, ce point est encore plus sensible. Un chatbot peut recevoir un identifiant pseudonyme dans l'interface, puis croiser ce signal avec l'historique de conversation, des métadonnées de session et un connecteur CRM. Si ces couches ne sont pas cloisonnées, la réidentification ne passe même plus par une action explicite. Elle devient un effet de bord du système.
Ce que la jurisprudence change pour les projets IA
Pour la direction générale, la lecture utile est la suivante. L'appréciation juridique dépend du contexte d'accès et des moyens raisonnablement disponibles pour identifier la personne. Autrement dit, un destinataire qui reçoit des données pseudonymisées sans disposer de la clé, ni d'un moyen réaliste de reconstituer l'identité, n'est pas dans la même position que l'entreprise qui orchestre l'ensemble du traitement.
Cette nuance crée une marge de manœuvre intéressante dans les projets IA externalisés. Un prestataire de modèle, d'annotation ou d'inférence peut intervenir sur des jeux pseudonymisés avec un niveau d'exposition plus faible, à condition que l'architecture, les contrats et les droits d'accès soient alignés. Le bénéfice n'est pas automatique. Il dépend de la séparation effective des rôles, des environnements et des capacités de réidentification.
Le responsable de traitement, lui, conserve sa responsabilité pleine et entière sur la chaîne. C'est le point que beaucoup de programmes IA sous-estiment. Le DPA rassure. Il ne corrige ni une fuite dans les logs, ni un export non autorisé, ni un connecteur qui recolle les identifiants au mauvais endroit.
Pour un dirigeant, le bon réflexe consiste à traiter la pseudonymisation comme un sujet de gouvernance opérationnelle, pas comme une simple option de sécurité. Il faut décider qui peut réidentifier, dans quel délai, pour quelle finalité, avec quel niveau de validation et avec quelle trace d'audit. Sans ce cadre, l'entreprise connaît la règle mais ne l'applique pas correctement. C'est précisément là que naissent les risques de non-conformité, surtout dans les déploiements d'IA où les flux de données sont continus et complexes.
Les Méthodes Techniques pour une Pseudonymisation Robuste
Dans les projets IA, l'écart entre théorie et exécution apparaît ici. Les équipes savent qu'il faut pseudonymiser. Elles se trompent souvent sur le point décisif, à savoir quelle technique appliquer à quel flux, à quel moment, et avec quel contrôle d'accès sur la réidentification.
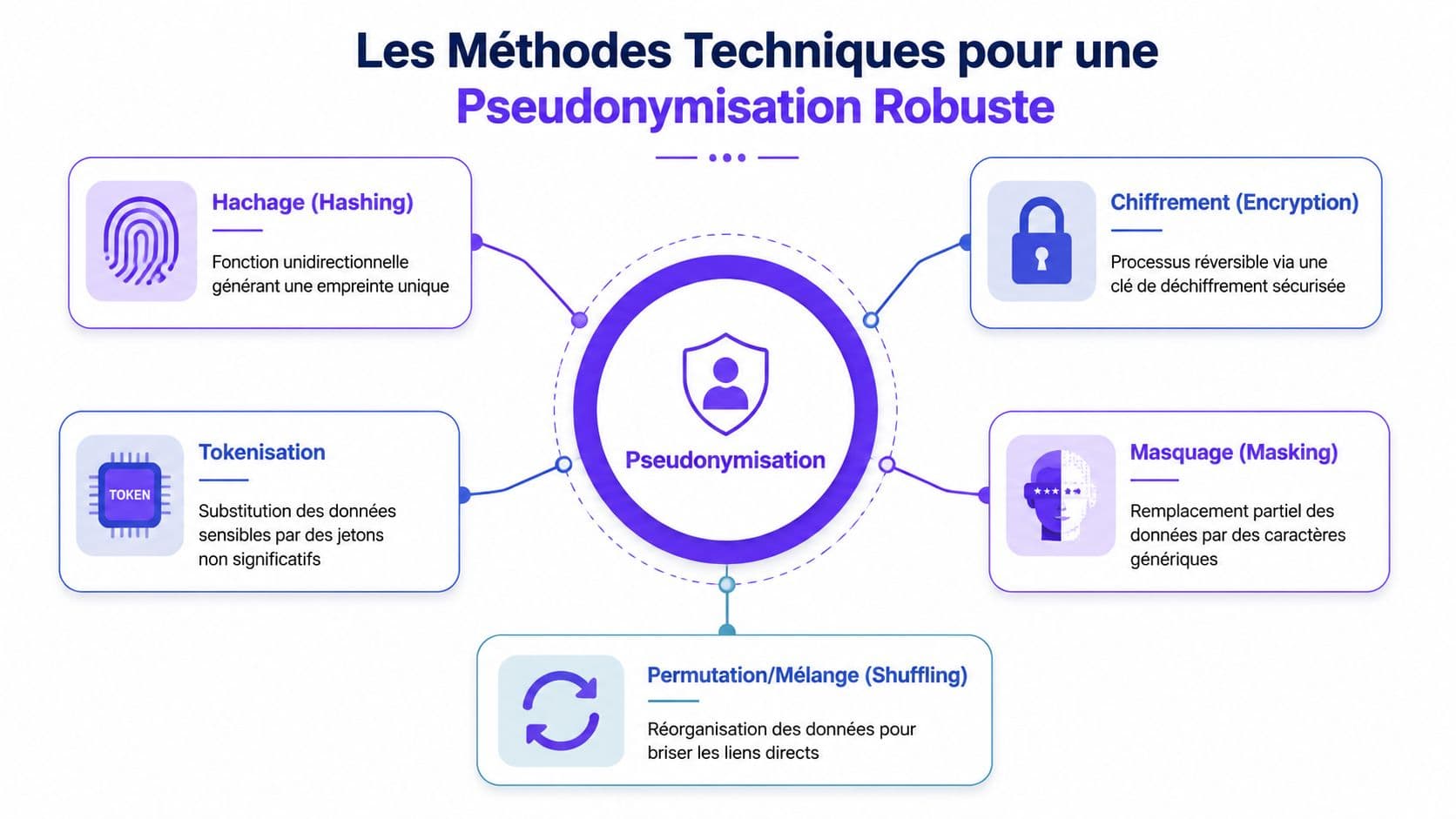
Choisir la bonne technique selon l'usage réel
La doctrine de la CNIL sur l'anonymisation et la réduction du risque de réidentification rappelle un point opérationnel simple. Une technique n'a de valeur que si l'environnement, les accès et les données de correspondance sont séparés de façon effective (analyse de la CNIL sur l'anonymisation et les critères techniques).
L'arbitrage se fait donc par usage.
- Hachage avec salage. Adapté si l'objectif est de rapprocher des enregistrements ou de limiter l'exposition d'un identifiant sans permettre un retour simple à l'identité. C'est utile pour la déduplication, certains contrôles de cohérence et une partie des usages analytiques. Ce n'est pas adapté si le métier doit réidentifier une personne dans un cadre autorisé.
- Chiffrement. Pertinent si la réversibilité est prévue et strictement encadrée. Il convient aux cas où un nombre limité d'acteurs habilités doit pouvoir revenir à l'identité pour traiter une demande client, un litige ou une obligation réglementaire. Le risque principal se concentre alors sur la gestion des clés, les habilitations et les journaux d'accès.
- Tokenisation. Souvent le meilleur choix dans les systèmes transactionnels et conversationnels. Le token remplace l'identifiant source tout en conservant une référence stable dans le temps. C'est généralement le modèle le plus praticable pour les assistants, les agents et les outils de support.
- Masquage. Utile pour l'affichage partiel, les environnements de test et certaines opérations de support. En pratique, le masquage seul couvre rarement l'ensemble du risque, surtout si d'autres champs ou pièces jointes permettent encore d'identifier la personne.
- Permutation ou mélange. Intéressant pour des jeux de données analytiques ou de démonstration. Beaucoup moins adapté aux parcours où il faut tracer une action, traiter un dossier ou conserver une continuité de service.
Une base documentaire alimentée par IA n'a pas besoin du nom civil d'un client pour retrouver une procédure, un niveau de SLA ou un scénario de réponse. Elle a besoin d'un identifiant stable, d'un contexte métier propre et d'une levée de pseudonyme soumise à validation. C'est le schéma recherché dans une base de connaissance IA pour le service client, où la connaissance opérationnelle circule sans exposer inutilement l'identité.
Ce qui tient en production, et ce qui casse
Le bon choix n'est pas la technique la plus impressionnante sur un schéma d'architecture. C'est celle que l'équipe sécurité, la DSI et les métiers peuvent maintenir sans créer de contournements.
Ce qui tient en production :
- Transformer les identifiants le plus tôt possible. Plus la pseudonymisation intervient en amont, moins les systèmes aval, les logs et les outils d'analyse accumulent des données directement identifiantes.
- Séparer les tables de correspondance, les clés et les rôles d'administration. Si la même équipe peut voir le token, la table de mapping et les exports applicatifs, le risque de réidentification remonte immédiatement.
- Tracer chaque levée de pseudonyme. L'entreprise doit pouvoir démontrer qui a accédé à l'identité, pour quelle finalité, sur quelle base et avec quelle approbation.
- Traiter les métadonnées comme un risque principal. Les identifiants reviennent souvent par les notes libres, les noms de fichiers, les pièces jointes, les transcripts, les URL ou les champs CRM secondaires.
- Tester les flux réels, pas seulement le design cible. Dans les projets de chatbot et d'agent IA, les fuites apparaissent souvent dans les prompts, les connecteurs, les exports CSV, les sauvegardes et les outils de monitoring.
Le rappel technique ci-dessous synthétise bien la logique :
Les échecs suivent presque toujours le même scénario. Une équipe chiffre correctement les données mais laisse trop d'administrateurs accéder aux clés. Un produit tokenise les comptes, puis transmet des pièces jointes non filtrées au moteur conversationnel. Un programme nettoie l'interface visible et oublie les sauvegardes, les exports de support ou les journaux applicatifs.
Une pseudonymisation sans gouvernance d'accès n'est pas un contrôle fiable.
Le test utile est simple. Identifiez tous les endroits où l'identité peut réapparaître sans procédure formelle, sans justification métier et sans trace d'audit. Dans un environnement IA, c'est là que le risque se matérialise vraiment.
Pseudonymisation et IA Le Duo Gagnant de la Conformité
L'IA a besoin de données utiles. Le RGPD exige de réduire l'exposition des personnes. La pseudonymisation est l'un des rares mécanismes qui réconcilient ces deux contraintes sans neutraliser la valeur opérationnelle des traitements.
Le bon modèle de circulation des données
Dans un dispositif bien conçu, les identifiants directs sont traités à l'entrée. Nom, e-mail, téléphone, numéro client ou éléments équivalents sont remplacés par un pseudonyme ou un token avant d'alimenter les briques de traitement conversationnel. L'agent travaille donc sur un contexte exploitable, mais dépourvu d'identité directe.
Une donnée pseudonymisée peut perdre son caractère personnel pour un sous-traitant, comme un fournisseur de chatbot IA, si ce dernier n'a aucun moyen raisonnable de ré-identifier les individus, conformément à un arrêt de la CJUE. Cela permet à l'agent IA de traiter les requêtes sans jamais connaître l'identité réelle du client (analyse juridique sur le rôle du sous-traitant).
C'est une opportunité forte pour les entreprises qui veulent déployer des agents IA sans exposer inutilement leur patrimoine de données. Le modèle cible est clair. L'entreprise garde la maîtrise de la réidentification. Le prestataire traite un signal utile mais non directement nominatif.
Pourquoi LLM sur NLP et agents IA sur RPA changent la donne
Les anciens schémas d'automatisation reposaient souvent sur des workflows rigides et des jeux de règles. Aujourd'hui, nous utilisons des LLM plutôt que du NLP classique, et des agents IA plutôt que du RPA quand l'objectif est de gérer des interactions client complexes, multicanales et évolutives.
Ce changement renforce l'intérêt de la pseudonymisation. Un agent IA traite de longs contextes, reformule, résume, classe, détecte des intentions et interroge plusieurs outils. Plus le raisonnement applicatif devient riche, plus il faut cloisonner l'identité. Sinon, la donnée personnelle se diffuse dans trop de couches.
Un exemple concret. Un client demande le suivi d'un dossier, une explication contractuelle et une mise à jour de coordonnées. L'agent n'a pas besoin de “voir” son nom pour comprendre l'intention, vérifier l'éligibilité de l'action ou préparer la réponse. Il a besoin d'un identifiant de session, d'un accès autorisé à certaines informations métier et d'une procédure d'escalade quand une action sensible exige une vérification supplémentaire.
Cette séparation entre compréhension, action et réidentification est souvent ce qui distingue un projet IA industrialisable d'un prototype risqué.
Déployer la Pseudonymisation en Pratique Le Processus Opérationnel
Le passage en production échoue rarement pour une raison purement juridique. Il échoue parce que les responsabilités sont floues, que les flux ne sont pas cartographiés ou que la gouvernance s'arrête au moment où l'application démarre.
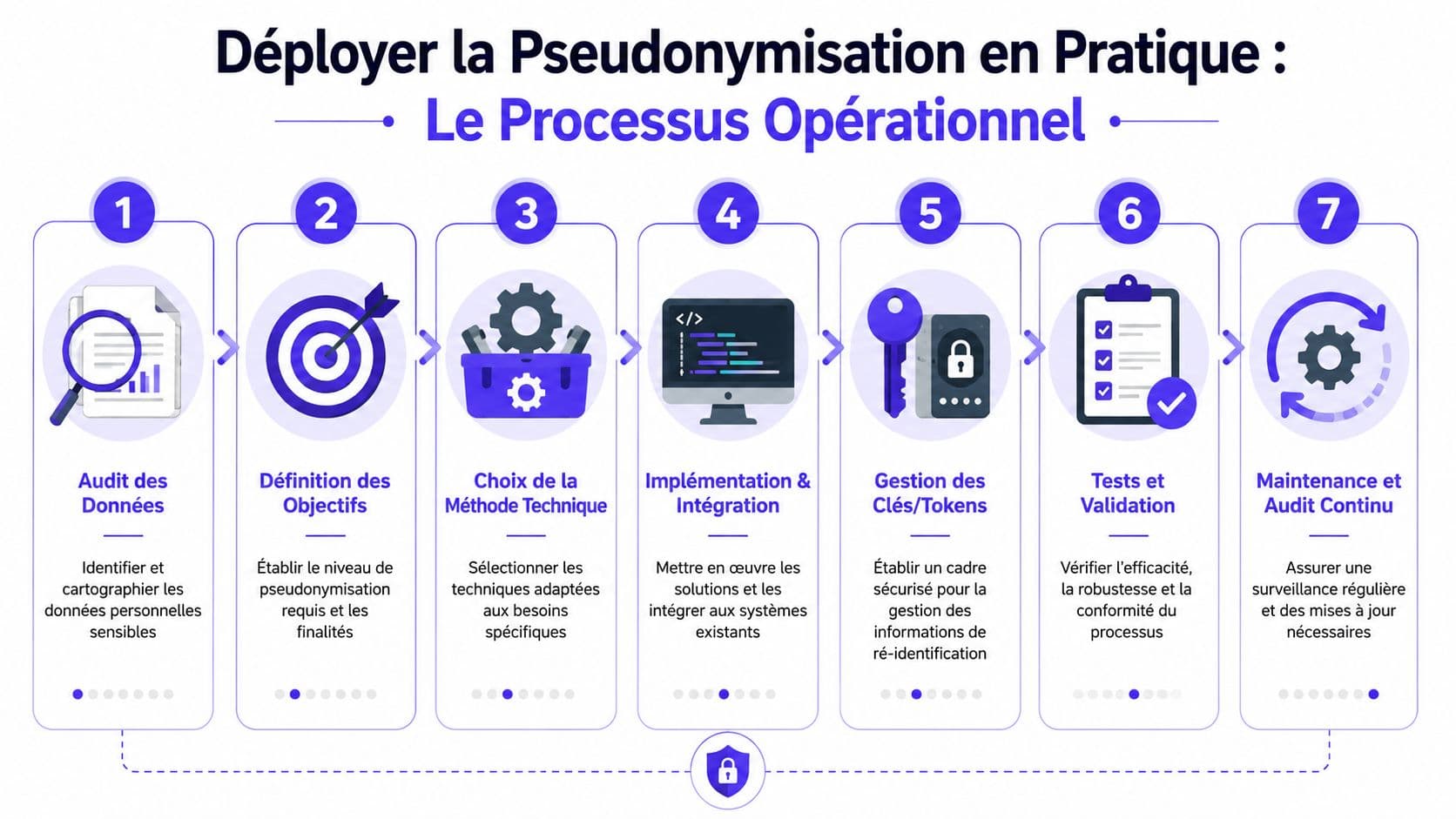
Le workflow opérationnel à instaurer
Un processus solide tient en sept blocs opérationnels.
- Cartographier les données réelles. Pas seulement les champs déclarés dans les applicatifs. Il faut inclure les prompts, logs, exports, transcripts, pièces jointes, historiques et jeux de test.
- Définir les finalités exactes. Analyse, assistance, routage, résolution, qualité, entraînement, supervision. Chaque finalité peut appeler une technique différente.
- Choisir la méthode de pseudonymisation par flux. Un même programme n'a pas besoin d'une seule méthode partout.
- Intégrer tôt dans le pipeline. Plus vous attendez, plus l'identité se réplique.
- Isoler la réidentification. Une équipe back-office ou un service habilité peut gérer les cas nécessitant un retour à l'identité, via des agents IA back-office ou des interfaces dédiées, mais hors du périmètre standard de traitement.
- Tester la réidentifiabilité. Il faut attaquer le système comme le ferait un utilisateur interne curieux ou un acteur malveillant motivé.
- Auditer en continu. Les menaces changent, les outils évoluent, les usages dérivent.
Les erreurs d'organisation les plus coûteuses
Le problème n'est pas seulement technique. Il est souvent managérial.
- Le projet est porté uniquement par la conformité. Sans DSI, sécurité, data et métier, la pseudonymisation reste théorique.
- Les habilitations sont héritées d'anciens modèles. Trop de personnes gardent des accès au nom de l'historique.
- Les exceptions deviennent la norme. Le support, l'analytics, la qualité ou la formation obtiennent des dérogations permanentes.
- La documentation n'est pas exploitable. En contrôle ou en incident, personne ne peut démontrer le cheminement exact d'une donnée.
Une bonne pseudonymisation n'est pas un module ajouté à la fin. C'est une discipline d'exploitation.
Les directions générales ont intérêt à demander une preuve simple. Montrez le parcours complet d'une donnée personnelle depuis la collecte jusqu'à son usage dans un agent IA. Si l'équipe ne peut pas le faire rapidement, le programme n'est pas encore mature.
Checklist de Mise en Œuvre et Prochaines Étapes
Une stratégie de pseudonymisation RGPD fiable tient sur une checklist exigeante. Si un seul maillon est faible, le programme devient difficile à défendre devant un RSSI, un DPO, un auditeur ou un comité exécutif.

Checklist exécutive
- Finalités cadrées. Chaque usage de la donnée est documenté et relié à une base légale claire.
- Flux cartographiés. Les données visibles et invisibles sont identifiées, y compris les logs et les exports.
- Technique adaptée au besoin. Hachage, chiffrement, tokenisation ou combinaison raisonnée selon le cas d'usage.
- Clés et tables de correspondance isolées. Séparation réelle, pas seulement déclarative.
- Accès gouvernés. Habilitations minimales, journalisation et revues régulières.
- Tests de réidentification organisés. Le dispositif est challengé dans des conditions réalistes.
- Documentation exploitable. Les équipes peuvent démontrer le fonctionnement du contrôle.
- Gestion d'incident prévue. Réaction claire si une donnée pseudonymisée est réidentifiée ou exposée.
Ce qu'un dirigeant doit exiger du programme
Un comité de direction n'a pas besoin de descendre au niveau de chaque algorithme. En revanche, il doit exiger trois garanties.
D'abord, une réduction réelle de l'exposition de l'identité dans les systèmes IA et conversationnels. Ensuite, une capacité prouvée à contrôler la réidentification. Enfin, une gouvernance capable de tenir dans la durée, malgré les évolutions de produits, de fournisseurs et d'équipes.
La pseudonymisation RGPD n'est pas un projet ponctuel. C'est une capacité d'entreprise. Bien menée, elle permet d'accélérer l'automatisation, d'ouvrir des cas d'usage IA plus ambitieux et de protéger la confiance client avec un niveau de rigueur compatible avec la réalité opérationnelle.
Si vous voulez déployer une IA conversationnelle performante sans improviser la conformité, Webotit.ai peut vous aider à cadrer l'architecture cible, isoler les données sensibles, structurer les flux de pseudonymisation et sécuriser le passage en production. Le plus utile, en général, est de partir d'un diagnostic concret des parcours, des risques de réidentification et des points de rupture entre métier, IT et conformité.