Optimisez votre intégration données pour l'IA en 2026
Optimisez votre intégration données pour l'IA en 2026
Maîtrisez l'intégration données (ETL, API) pour vos agents IA. Guide sur l'architecture et la conformité RGPD pour garantir un ROI maximal en 2026.
Parler de ce sujet avec Webotit
Votre agent IA est prêt en démo. Il répond bien, suit les consignes, retrouve la documentation produit. Puis le projet entre dans le réel. Un client demande où en est son dossier, si son contrat couvre un cas précis, pourquoi sa commande est bloquée, ou si un paiement a bien été pris en compte. L'agent hésite, répond partiellement, ou escalade trop vite. Le problème n'est généralement pas le modèle. Le problème, c'est l’intégration données.
C'est le point de rupture le plus fréquent dans les projets d'automatisation de la relation client. Les données utiles existent déjà, mais elles sont dispersées entre CRM, ERP, outil ticketing, base documentaire, téléphonie, messagerie, parfois plusieurs applications métier. Tant que ces flux ne sont pas unifiés proprement, un agent IA reste un bon démonstrateur, pas un vrai composant opérationnel.
Le sujet est d'autant plus mal traité que les contenus publics en France sur l’« intégration données » se concentrent surtout sur des cas statiques, alors que le défi concret des DSI consiste à intégrer en continu des flux client multi-sources avec faible latence, conformité RGPD et traçabilité complète. Cette lacune explique pourquoi environ 65-70 % des directions Service Client déclarent ne pas maîtriser la pile technique nécessaire pour dépasser les 60 % de résolution sans agent, comme le rappelle cette analyse sur le manque de ressources opérationnelles autour de l'intégration. C'est précisément le type de sujet que les équipes explorent lorsqu'elles cadrent des solutions d'automatisation conversationnelle.
L'intégration de données une fondation sous-estimée
Beaucoup d'équipes pensent encore qu'un projet d'agent IA démarre par le choix du LLM. En pratique, il démarre par une question plus terre à terre. Quelles données l'agent peut-il lire, à quel moment, avec quel niveau de confiance, et sous quel contrôle ?
Quand cette réponse est floue, les symptômes apparaissent vite. Le chatbot connaît les FAQ mais ignore l'état réel d'une commande. Le callbot comprend l'intention mais ne retrouve pas le bon dossier. Le mailbot classe correctement une demande, sans pouvoir déclencher l'action suivante dans le SI. L'expérience utilisateur paraît moderne en façade, mais le back-office continue à compenser manuellement.
Ce qui échoue le plus souvent
Les approches traditionnelles ratent leur cible pour une raison simple. Elles ont été conçues pour consolider des données, pas pour alimenter des décisions conversationnelles en temps réel.
On voit souvent les mêmes erreurs :
- Des synchronisations batch trop lentes qui laissent l'agent répondre avec un statut périmé.
- Des mappings métier incomplets entre objets proches en apparence, mais différents en logique. Un “client” du CRM n'est pas toujours le “titulaire” d'un contrat dans l'outil métier.
- Une couche documentaire sans lien transactionnel. L'agent sait expliquer une procédure, mais pas dire si elle s'applique à ce client.
- Une gouvernance repoussée à plus tard. Les équipes branchent d'abord, documentent ensuite. C'est l'inverse qu'il faut faire.
Une réponse correcte mais non contextualisée reste une mauvaise réponse en relation client.
Pourquoi le sujet devient stratégique
L'intégration n'est pas un chantier annexe du programme IA. C'est la couche qui détermine si l'automatisation produit du service réel, ou seulement de la déviation de flux. Quand l'intégration est bien conçue, l'agent peut assembler contexte client, règles métier, historique d'échanges et état transactionnel dans une seule réponse exploitable.
Le retour sur investissement vient de là. Pas d'une promesse abstraite d'IA. Il vient d'une baisse des escalades inutiles, d'un meilleur aiguillage, d'un traitement plus homogène, et d'une capacité à opérer sur plusieurs canaux sans reconstruire la logique à chaque fois.
Le bon changement de perspective
Le sujet n'est donc pas “comment connecter mes outils”. Le vrai sujet est “comment construire une chaîne de confiance entre mes systèmes et mes agents IA”.
Cette nuance change tout. Elle oblige à penser source fiable, latence acceptable, règles d'accès, observabilité et actions possibles. Sans cette fondation, les promesses d'automatisation restent fragiles.
Qu'est-ce que l'intégration de données en pratique
L'intégration de données, en pratique, joue le rôle d'un traducteur universel entre systèmes qui ne parlent ni le même format, ni le même rythme, ni la même logique métier. Un CRM comme Salesforce structure des comptes, des contacts et des opportunités. Un ERP comme SAP raisonne en commandes, factures et livraisons. Un outil de support comme Zendesk stocke des tickets. Une base documentaire contient des procédures. Un agent IA a besoin que tout cela devienne un contexte cohérent.
Une vue client unifiée, pas un simple copier-coller
Il faut distinguer synchronisation et intégration.
La synchronisation copie ou met à jour des enregistrements entre deux systèmes. C'est utile, mais insuffisant. L'intégration, elle, construit une vue exploitable par un processus métier ou un agent. Elle résout les identifiants, harmonise les statuts, enrichit les événements, applique des règles de priorité et garde la trace de ce qui a été utilisé.
Prenons un cas simple. Un client écrit pour demander pourquoi sa livraison n'est pas arrivée. Une synchronisation basique peut rapatrier son contact depuis le CRM. Une vraie intégration va aussi récupérer la commande dans l'OMS, le statut logistique, l'éventuel incident de paiement, la promesse de livraison et l'historique des échanges. L'agent ne “voit” pas cinq systèmes. Il voit une situation.
Pour des cas internes, la logique est la même. Un agent IA back-office n'est utile que s'il lit les bons objets métier et déclenche la bonne suite d'actions sans demander à un collaborateur de recoller les morceaux.
Ce que l'agent doit recevoir au bon moment
Un agent IA n'a pas besoin de toutes les données. Il a besoin des bonnes données, au bon niveau de fraîcheur, avec un niveau de confiance clair.
En architecture, cela impose trois choix :
- Le périmètre fonctionnel. Quelles questions l'agent doit-il traiter de bout en bout, et lesquelles doivent rester assistées.
- Le niveau de contextualisation. Faut-il seulement lire un statut, ou aussi interpréter une règle d'éligibilité, un historique de sinistre ou une politique commerciale.
- Le mode d'accès. Lecture directe par API, alimentation dans un entrepôt, requête fédérée, indexation documentaire, ou combinaison de plusieurs approches.
Règle terrain : si l'agent ne peut pas justifier sa réponse par une source, un statut ou une règle métier identifiable, il ne faut pas lui confier un parcours sensible.
L'intégration de données ne consiste donc pas à “faire circuler de la donnée”. Elle consiste à rendre les systèmes interopérables pour une décision immédiate. C'est cette différence qui sépare un bot décoratif d'un agent réellement utile.
Comparatif des approches ETL ELT CDC et API
Le choix d'une méthode d'intégration dépend moins d'une préférence d'architecture que du type de parcours que vous voulez automatiser. Si vous traitez du reporting, un batch nocturne peut suffire. Si vous pilotez un agent conversationnel qui doit lire un dossier pendant un appel ou pendant un échange par email, la tolérance à la latence est très différente.
L'erreur classique consiste à choisir une seule approche pour tout le SI. En réalité, les meilleures architectures combinent plusieurs méthodes. Le sujet est de savoir où placer la transformation, quand propager un changement, et quelle partie du système devient la référence opérationnelle.
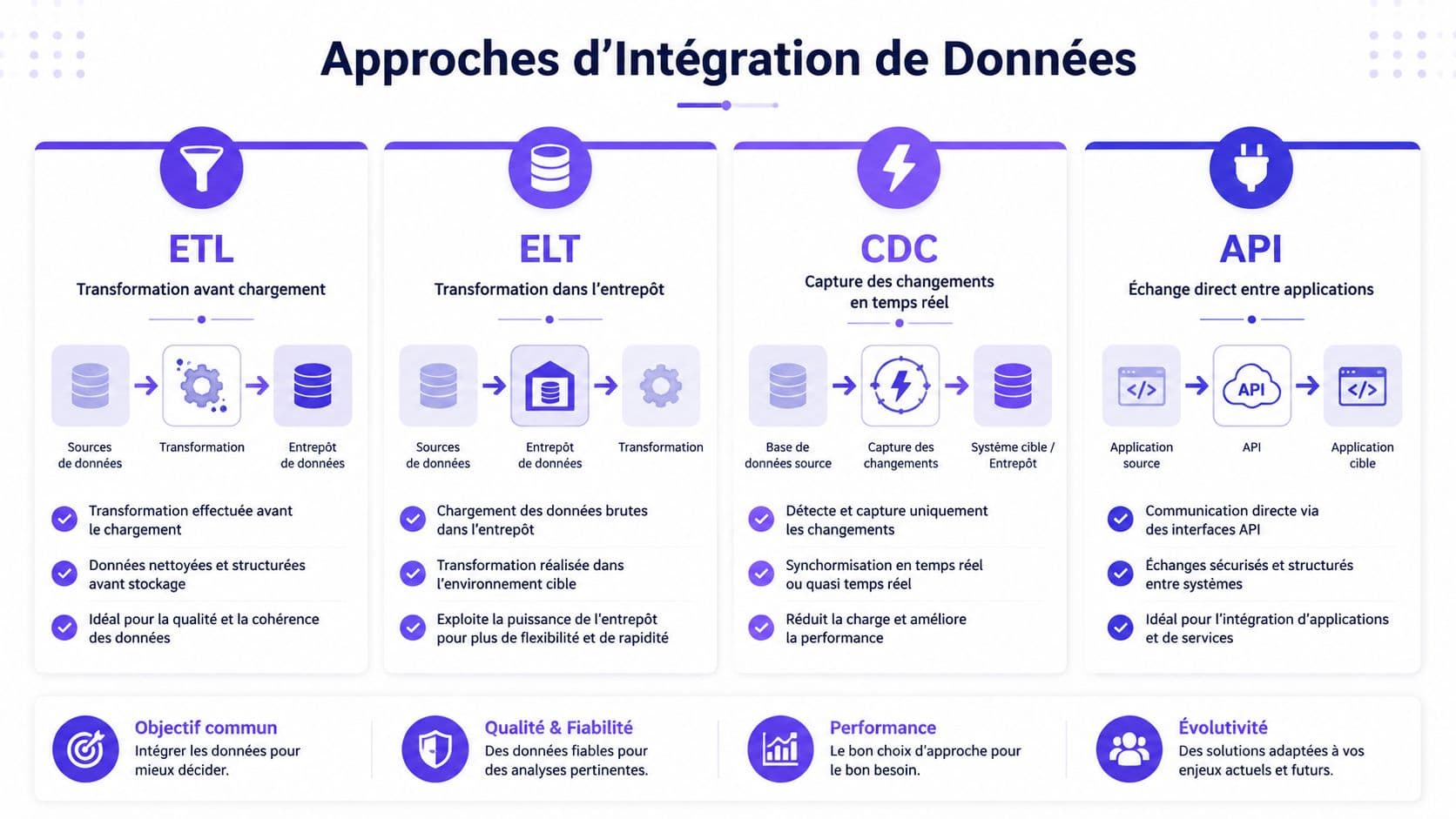
Le tableau de décision
| Méthode | Principe | Idéal Pour | Avantage Clé | Inconvénient |
|---|---|---|---|---|
| ETL | Extraction, transformation puis chargement | Reporting stabilisé, consolidation historique, flux prévisibles | Contrôle fort avant entrée en cible | Plus rigide pour les changements fréquents et moins adapté au temps réel |
| ELT | Extraction, chargement puis transformation dans la cible | Plateformes cloud, données hétérogènes, usages IA et analytics | Grande flexibilité sur les transformations et disponibilité plus rapide des données | Demande une cible bien gouvernée et une bonne maîtrise des coûts de calcul |
| CDC | Capture des changements à la source | Réplication incrémentale, mise à jour quasi continue, événements métier | Très utile pour éviter les rechargements complets | Plus complexe à opérer si les schémas bougent souvent |
| API | Échange direct entre applications | Consultation temps réel, déclenchement d'actions, lecture contextuelle | Très précis pour exposer des services métier | Dépendance forte aux contrats d'API, à la qualité des endpoints et à la charge des systèmes sources |
Pourquoi ELT domine souvent en SaaS temps réel
Dans les déploiements SaaS orientés agents IA, ELT est souvent la meilleure colonne vertébrale pour tout ce qui relève de la préparation contextuelle. L'approche consiste à charger d'abord les données brutes, puis à appliquer les transformations dans la plateforme cible. D'après l'explication d'Alumio sur les méthodes d'intégration, cette logique exploite la puissance du cloud cible, réduit la latence des interactions conversationnelles, augmente la flexibilité pour les transformations métier et s'adapte bien aux données non structurées comme les transcriptions vocales ou les emails.
Concrètement, cela change trois choses pour une plateforme d'agents IA :
- Vous conservez la matière brute plus longtemps. C'est précieux quand les équipes métier revoient les règles de catégorisation ou les enrichissements.
- Vous séparez ingestion et interprétation. Une demande email peut être chargée rapidement, puis enrichie avec des règles propres à l'assurance, à la banque ou au retail.
- Vous facilitez l'évolution du pipeline. Quand un nouveau canal arrive, vous n'avez pas à réécrire toute la chaîne amont.
Là où ETL, CDC et API restent indispensables
ETL n'a pas disparu. Il reste pertinent quand l'environnement impose une validation stricte avant chargement, ou quand la cible doit recevoir des données déjà normalisées. Dans certains SI historiques, c'est même le seul mode acceptable.
CDC est souvent la bonne réponse pour suivre les changements utiles sans déplacer l'ensemble des tables. Si un statut de dossier ou de commande change fréquemment, cette méthode évite de recalculer tout le monde pour un seul événement.
Les API, elles, sont irremplaçables quand l'agent doit agir et pas seulement lire. Créer un ticket, mettre à jour un dossier, envoyer une confirmation ou déclencher un workflow nécessite des contrats applicatifs explicites.
Le bon design n'oppose pas ETL, ELT, CDC et API. Il répartit chaque méthode là où elle produit le moins de friction opérationnelle.
Pour un dispositif conversationnel moderne, le schéma le plus efficace reste souvent mixte. ELT pour préparer et enrichir. CDC pour suivre les changements. API pour lire finement ou exécuter une action. ETL pour les zones où la gouvernance ou les systèmes hérités l'imposent encore.
Architectures d'intégration pour agents IA conversationnels
Une architecture d'intégration pour agents IA conversationnels ne ressemble pas à un simple alignement de connecteurs. Elle doit servir une chaîne d'exécution complète. Comprendre la demande, récupérer le bon contexte, interroger les sources pertinentes, appliquer les règles métier, générer une réponse, puis journaliser l'ensemble pour supervision et audit.
Le bus d'intégration comme noyau opérationnel
Dans les déploiements sérieux, il faut une couche centrale qui orchestre les flux. Peu importe qu'on l'appelle bus d'intégration, couche d'orchestration, middleware événementiel ou façade de services. Sa fonction reste la même. Abstraire la complexité des systèmes sources pour éviter que chaque agent parle directement à chaque application.
Cette couche reçoit des événements ou des requêtes venant du web, du mobile, de la voix ou de l'email. Elle sait ensuite où aller chercher l'information pertinente dans Salesforce, SAP, Zendesk, Guidewire, un PIM, un OMS ou une base documentaire. Elle applique aussi les règles d'accès. Un client final ne doit pas voir la même chose qu'un gestionnaire. Un callbot ne doit pas manipuler les mêmes opérations qu'un agent de back-office.
Un autre bénéfice est souvent sous-estimé. Cette couche réduit la dépendance à une compétence rare. Dans beaucoup d'équipes, les profils capables de relier architecture, métier, données et IA sont peu nombreux. Pour des organisations qui structurent ces compétences, un bon repère est d'observer comment un CV sur mesure pour futurs développeurs met en avant la combinaison entre logique applicative, intégration et compréhension des outils, car c'est précisément ce mélange qui manque dans beaucoup de programmes IA.
Le rôle du RAG et des règles métier
Le RAG n'est fiable que si les documents et les données transactionnelles sont bien reliés. Si votre agent sait retrouver une procédure de remboursement mais ne peut pas vérifier l'état de la commande ou l'éligibilité du client, il inventera des passerelles que votre SI n'a jamais validées.
L'architecture solide sépare donc plusieurs couches :
- La couche conversationnelle, qui gère l'intention, le ton, le canal et le pilotage du dialogue.
- La couche de récupération, qui sait interroger les bonnes sources documentaires et métier.
- La couche de décision, qui applique règles, seuils, permissions et critères d'escalade.
- La couche d'action, qui pousse une mise à jour via API ou déclenche un workflow.
Un agent IA fiable ne répond pas seulement avec du texte. Il répond avec du contexte, des contraintes et une capacité d'action bornée.
C'est dans ce type d'assemblage que des agents IA d'entreprise deviennent utiles sur plusieurs canaux. La valeur ne vient pas d'un LLM isolé. Elle vient d'un système où chaque réponse peut être reliée à une source, à une règle et à un état métier.
Gouvernance et conformité des données intégrées
Dans un environnement régulé, la gouvernance n'arrive pas après l'intégration. Elle en fixe les limites dès le départ. C'est particulièrement vrai quand les flux concernent des contrats, des paiements, des sinistres, des dossiers administratifs ou des échanges vocaux.
L'erreur la plus coûteuse consiste à multiplier les copies “temporaires”. Elles sont souvent créées pour aller plus vite. Elles finissent par compliquer les audits, brouiller la responsabilité sur la donnée et exposer inutilement des informations personnelles.

Moins déplacer les données pour mieux gouverner
Pour les environnements régulés, l’intégration fédérée est souvent un choix d'architecture très pertinent. Dans ce modèle, les données restent dans leurs systèmes d'origine et les requêtes s'exécutent en temps réel sans déplacement physique des données. IBM l'explique clairement dans sa présentation de l'intégration fédérée et de la virtualisation des données. Cette approche réduit les risques de conformité en minimisant les copies de données personnelles et maintient la traçabilité complète à la source.
Ce n'est pas une solution universelle. Elle impose une vraie discipline sur la performance réseau, la disponibilité des systèmes sources et le design des requêtes. Mais dans des secteurs où l'audit compte autant que la vitesse, le compromis est souvent favorable.
Pour un callbot de suivi de dossier, par exemple, il est souvent préférable d'interroger la source autoritative plutôt que de répliquer plusieurs fois le même état dans des caches mal maîtrisés. C'est aussi la logique qu'on retrouve dans des parcours comme le callbot de suivi de dossier, où la confiance dans l'état restitué compte autant que la fluidité de la réponse.
La traçabilité comme exigence d'exploitation
La traçabilité n'est pas un bonus documentaire. C'est une capacité d'exploitation. Il faut savoir quelle source a été interrogée, quelle variable a été utilisée, quelle transformation a été appliquée et quelle version d'une règle métier a conduit à la réponse.
Sur le terrain, cela implique au minimum :
- Un lineage lisible entre source, transformation et objet consommé par l'agent.
- Des journaux d'exécution utiles pour les équipes support, conformité et produit.
- Une politique de minimisation qui évite de charger des données inutiles “au cas où”.
- Une séparation nette des environnements pour tester sans brouiller les flux de production.
Si une équipe ne peut pas reconstituer pourquoi un agent a répondu ce qu'il a répondu, elle n'a pas encore un système industrialisé.
Les organisations qui avancent vite sur l'IA ne sont pas celles qui relâchent la gouvernance. Ce sont celles qui l'intègrent à l'architecture dès les premiers connecteurs.
Exemples concrets par secteur d'activité
Les arbitrages d'intégration deviennent plus clairs dès qu'on regarde des scénarios métier. Pas des promesses générales. Des situations où l'agent doit produire une réponse utile, sourcée et exploitable.
Assurance
Avant intégration, un client demande si un dégât précis est couvert. Le chatbot sait décrire la garantie standard, mais il ne sait ni identifier le bon contrat, ni vérifier les exclusions, ni voir si un sinistre similaire est déjà ouvert. Le conseiller reprend la main presque systématiquement.
Après intégration, l'agent croise contrat, référentiel produit, dossier en cours et base de connaissances. Il ne donne pas un avis juridique improvisé. Il restitue le périmètre applicable, demande les pièces manquantes si nécessaire, ou oriente vers l'étape suivante. Le gain principal n'est pas seulement la rapidité. C'est la cohérence de traitement.
Dans ce type de cas, la leçon utile vient d'un autre univers. L'INSEE applique une logique de qualification de la source avant intégration. La qualité de la donnée est évaluée avant usage, et seules les informations fiables et nécessaires sont retenues, comme l'explique le Courrier des statistiques de l'INSEE sur l'intégration des données administratives. C'est une excellente discipline pour tout pipeline IA.
Banque
Avant intégration, un client appelle pour signaler une opération inhabituelle. Le callbot détecte l'intention, mais sans accès contextualisé aux transactions, aux statuts de carte et aux règles de sécurité, il ne peut que transférer.
Après intégration, le système relie identité, événements récents, statut du moyen de paiement et script de qualification. L'agent conversationnel peut alors poser les bonnes questions, guider le client, et déclencher l'escalade vers le bon circuit. La qualité de service vient ici du bon ordre des vérifications, pas d'un langage plus fluide.
E-commerce
Avant intégration, le chatbot vendeur recommande un produit disponible dans le catalogue, sans voir les contraintes de stock, de variante ou de livraison. La réponse semble pertinente, puis le client découvre la rupture au moment du panier.
Après intégration, l'agent lit le PIM, l'OMS, les règles promotionnelles et le contexte du compte client. Il peut proposer une alternative crédible, expliquer le délai, ou confirmer qu'un article est bien compatible avec une commande existante. Sur des parcours de chatbot relation client, c'est ce niveau de branchement métier qui transforme un bot de FAQ en véritable assistant commercial et support.
Checklist pour réussir votre projet d'intégration
Une bonne intégration de données commence rarement par un grand programme transverse. Elle commence par un périmètre clair, des sources qualifiées et un cas d'usage où la chaîne complète peut être observée.
Voici la checklist que j'utilise pour cadrer un projet d'agents IA d'entreprise :
-
Choisissez un parcours métier précis. Ne démarrez pas par “le service client”. Démarrez par un flux concret, comme le suivi de dossier, la qualification email ou le statut de commande.
-
Inventoriez les sources réellement utiles. Séparez ce qui est indispensable de ce qui est simplement disponible. Beaucoup de projets ralentissent parce qu'ils veulent tout intégrer dès le départ.
-
Identifiez la source autoritative pour chaque donnée. Un statut de contrat, un solde, une disponibilité produit ou un ticket ouvert ne doivent pas avoir plusieurs vérités concurrentes.
-
Décidez la méthode par flux. API pour agir ou lire finement. ELT pour préparer des données hétérogènes. CDC pour suivre les changements. ETL si le contexte legacy l'impose.
-
Écrivez les règles métier avant le prompt. Les équipes perdent du temps à optimiser les formulations alors que l'ambiguïté vient souvent des règles d'éligibilité, de priorité ou d'escalade.
-
Documentez le lineage dès le premier lot. Si vous attendez la phase d'audit pour le faire, vous le ferez mal et trop tard.
-
Prévoyez la supervision humaine. Un agent utile n'est pas un agent laissé seul. Il faut des seuils de confiance, des mécanismes de reprise et des traces exploitables.
-
Mesurez des résultats métier simples. Qualité de réponse, taux d'escalade, temps de traitement, stabilité opérationnelle. Sans cela, l'intégration reste perçue comme un coût technique.
L'intégration données n'est pas un prérequis administratif de l'IA. C'est le moteur discret qui permet à un agent de répondre juste, d'agir proprement et de rester gouvernable.
Si vous devez connecter CRM, ERP, emails, voix et bases documentaires pour des agents IA exploitables en production, Webotit.ai peut servir de point de départ utile. La plateforme propose des agents conversationnels orchestrés, des intégrations API sécurisées, un cadre RGPD natif, une traçabilité complète, ainsi qu'un déploiement en mode SaaS ou on-premise. Le plus utile en phase de cadrage reste souvent le diagnostic initial pour identifier les quick wins, qualifier les sources et choisir la bonne architecture d'intégration.