Transparence IA: obligations & mesures techniques 2026
Transparence IA: obligations & mesures techniques 2026
Assurez la transparence IA de vos agents conversationnels. Découvrez nos guides sur les obligations (AI Act, RGPD) et les mesures techniques à déployer en 2026.
Parler de ce sujet avec Webotit
Le sujet de la transparence IA est souvent traité comme une question d'éthique ou de communication. En pratique, le vrai sujet est plus brutal. Quand la documentation est faible, l'audit devient presque impossible. Une étude sur des produits d'IA médicale commercialisés en Europe a mesuré des scores de transparence allant de 6,4 % à 60,9 %, avec une médiane de 29,1 %, et des lacunes récurrentes sur les données d'entraînement et les limites de déploiement (analyse publiée sur PubMed Central).
Pour une DSI, un directeur métier ou un responsable de la relation client, la conséquence est simple. Si vous ne pouvez pas expliquer d'où vient une réponse, dans quel cadre elle est fiable, et quand un humain doit reprendre la main, vous n'avez pas un agent IA pilotable. Vous avez une boîte noire branchée sur un processus métier.
C'est exactement là que la transparence IA devient opérationnelle. Elle ne consiste pas à exposer tous les détails internes d'un modèle. Elle consiste à rendre un système compréhensible, traçable et gouvernable pour les équipes qui le déploient, le contrôlent et répondent devant les clients, le DPO, l'audit interne ou le régulateur.
Pourquoi la transparence de l'IA n'est plus une option
29,1 %. Ce niveau médian de transparence observé dans une étude européenne sur des produits d'IA médicale, déjà cité plus haut, donne un ordre de grandeur utile. Le sujet dépasse largement la santé. Dès qu'un système d'IA influence une réponse client, une décision interne ou un traitement de données personnelles, l'absence de traçabilité devient un risque de déploiement.
Sur le terrain, le test est simple. Un client conteste une réponse. Le juridique demande sur quelle base elle a été produite. Le responsable métier veut savoir si l'agent s'est appuyé sur une source validée, sur une règle interne, ou sur une génération libre du modèle. Si l'entreprise ne peut pas reconstituer cette chaîne en quelques minutes, elle n'a pas un sujet d'éthique abstraite. Elle a un problème opérationnel, de conformité et de pilotage.
Trois risques concrets
-
Risque de conformité
Un agent qui n'indique pas clairement qu'un utilisateur interagit avec une IA, ou qui ne permet pas d'expliquer le traitement réalisé sur des données personnelles, expose l'entreprise à un risque immédiat au regard de l'AI Act et du RGPD. -
Risque opérationnel
Sans journaux d'exécution, sans versioning des prompts, sans références documentaires et sans règle d'escalade, un incident ne se corrige pas proprement. Il se contourne, puis il revient. -
Risque de confiance
Un client peut accepter une réponse imparfaite. Il accepte beaucoup moins une réponse impossible à vérifier, sans source, et sans reprise rapide par un humain.
Le critère utile est celui-ci. Un agent est transparent si un responsable métier peut expliquer ce qu'il a fait, pourquoi il l'a fait, et comment reprendre la main, sans mobiliser l'équipe data à chaque anomalie.
C'est le point que beaucoup de projets ratent. La transparence ne se résume pas à afficher “réponse générée par IA”. En production, il faut des preuves exploitables. Sources consultées, instructions système en vigueur, garde-fous métier appliqués, score ou seuil de confiance, historique d'escalade, corrections humaines, durée de conservation des logs. C'est à ce moment que la transparence IA devient opérationnelle.
Il y a aussi un arbitrage d'architecture. Un LLM seul donne une réponse rapide, mais il documente mal son propre cheminement et complique l'audit. Une architecture orchestrée permet de relier génération, contrôle documentaire, journalisation et supervision. C'est la logique mise en œuvre dans des plateformes d'orchestration conversationnelle et d’agents IA pour l'automatisation des interactions.
En 2026, en France, ce sujet ne relèvera plus d'une simple bonne pratique. Pour une DSI ou une direction métier, la transparence devient une condition de déploiement soutenable. Ceux qui lancent un agent sans cadre de preuve créent une dette de conformité et une dette de support. Ceux qui cadrent la traçabilité dès le départ gagnent quelque chose de beaucoup plus concret, la capacité d'auditer, de corriger et d'industrialiser sans perdre le contrôle.
Les trois piliers de la transparence en IA
Une bonne analogie est celle d'une cuisine professionnelle. Vous pouvez juger un plat sur trois plans. Les ingrédients utilisés, la recette suivie, et la décision du chef au moment du service. Pour un agent conversationnel, la transparence IA repose sur le même triptyque.
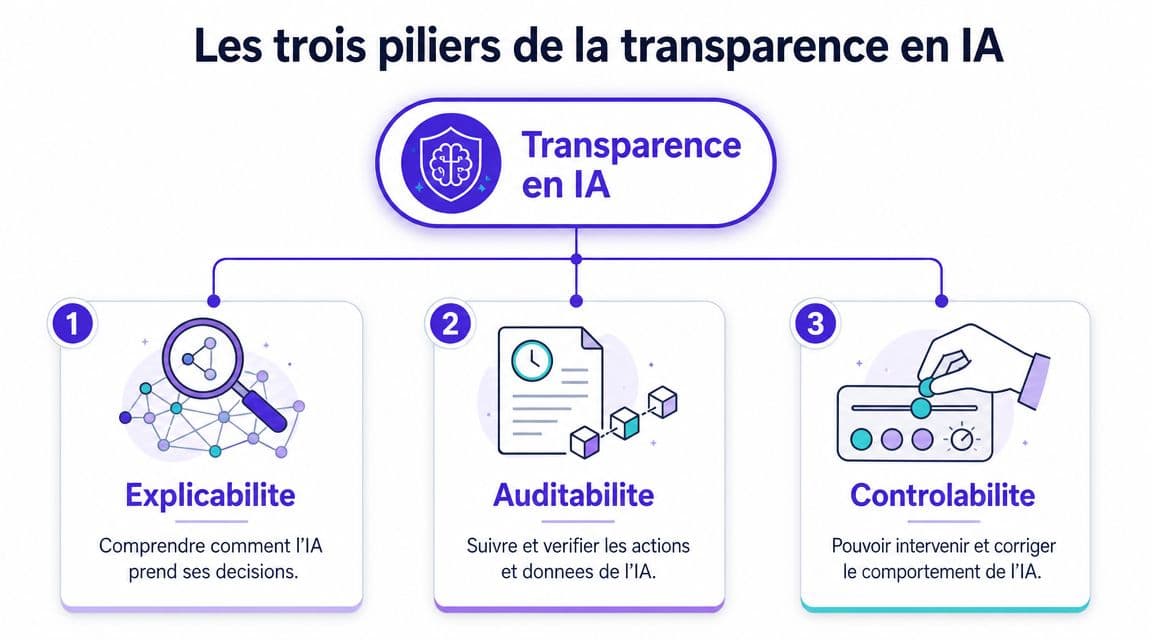
Premier pilier, savoir sur quoi l'agent s'appuie
Le premier pilier concerne la matière première. Un agent répond-il à partir d'une base documentaire validée, de contenus publics récupérés automatiquement, de données internes, ou d'un mélange des trois ?
Dans un dispositif sérieux, la réponse ne devrait jamais être “un peu de tout, on ne sait pas exactement”. La CNIL rappelle que les utilisateurs doivent recevoir une information claire sur l'existence d'un traitement automatisé et, quand c'est pertinent, sur sa logique générale. Le vrai enjeu n'est pas “d'ouvrir la boîte noire”, mais de fournir une documentation utile, compréhensible et actionnable (rappel cité dans cette publication scientifique).
Concrètement, cela impose de documenter :
-
Les sources autorisées
Base de connaissances interne, FAQ, CGV, scripts centre de contact, procédures qualité. -
Les sources exclues
Documents obsolètes, espaces collaboratifs non validés, données sensibles non nécessaires. -
Le mode de mise à jour
Qui publie, qui valide, et à partir de quand une nouvelle version devient la référence.
Une transparence IA utile ne promet pas l'omniscience. Elle précise le périmètre documentaire de l'agent.
Deuxième pilier, rendre le comportement intelligible
L'explicabilité n'exige pas de transformer un LLM en manuel de mathématiques. Elle exige de pouvoir répondre à des questions simples. Pourquoi cette réponse. Pourquoi cette action. Pourquoi cette proposition d'escalade.
Cette vidéo donne un bon cadre de lecture avant de passer à l'implémentation.
Dans la pratique, l'explication utile pour un métier tient souvent en trois éléments :
| Élément | Ce que l'équipe doit voir |
|---|---|
| Contexte | Intention détectée, pièces consultées, règles métier déclenchées |
| Limites | Cas où la réponse est incertaine ou hors périmètre |
| Action | Réponse donnée, demande de précision, ou transfert à un humain |
Une explication qui n'aide ni l'utilisateur final, ni le superviseur, ni l'audit interne n'est pas une explication utile.
Troisième pilier, garder la main sur la décision
La contrôlabilité est le pilier le plus sous-estimé. Un agent transparent n'est pas seulement un agent qui montre. C'est un agent qu'on peut arrêter, corriger, restreindre ou faire escalader.
Cela implique des choix très concrets :
- seuils d'escalade vers un conseiller
- règles d'interdiction sur certains cas d'usage
- journal des corrections humaines
- versioning des consignes système et des règles métier
Dans beaucoup de projets, c'est là que la maturité se voit. Les équipes les plus solides n'essaient pas de tout automatiser. Elles définissent précisément où l'agent est autonome, où il assiste, et où il se retire.
Comprendre vos obligations légales avec l'AI Act et le RGPD
Pour un agent conversationnel déployé en France, le sujet n'est pas seulement juridique. C'est un sujet d'exploitation. Une obligation mal traduite dans le produit finit en incident client, en audit interne pénible, ou en blocage du déploiement par la DPO ou la sécurité.

L'AI Act et le RGPD demandent surtout trois choses. Signaler l'usage de l'IA au bon moment. Documenter ce que fait réellement le système. Garder une capacité de contrôle humain adaptée au risque. Dit autrement, la transparence ne se limite pas à une mention légale en bas d'écran. Elle doit apparaître dans l'interface, dans les procédures de support, dans la documentation fournie aux équipes métier et dans les traces conservées en cas de contestation.
Les obligations immédiates à ne pas rater
L'AI Act prévoit des obligations de transparence immédiates dans plusieurs cas. C'est le cas quand une personne interagit avec une IA, quand le système génère du contenu synthétique, ou dans certains usages plus sensibles comme la reconnaissance d'émotions, la catégorisation biométrique, les deepfakes et certains contenus d'intérêt public. Le principe opérationnel est simple. La personne concernée doit pouvoir comprendre qu'elle échange avec une machine ou qu'elle consulte un contenu généré artificiellement (présentation de l'article 50).
Pour un agent conversationnel, cela se traduit par des choix précis dans le parcours :
-
Informer dès le premier écran ou le premier tour de conversation
La mention doit être visible, compréhensible et placée avant que l'utilisateur ne confonde l'agent avec un conseiller. -
Qualifier les sorties générées
Si l'agent produit du texte, de l'audio ou des résumés, l'organisation doit pouvoir identifier ce qui a été généré et dans quel contexte. -
Prévoir un recours humain réel
Un simple bouton “contact” caché dans le pied de page ne suffit pas si l'agent traite des demandes à impact client ou salarié.
Le RGPD ajoute une contrainte souvent sous-estimée par les équipes produit. L'information doit être intelligible pour la personne concernée, et cohérente avec le traitement réellement mis en œuvre. En pratique, il faut aligner la bannière ou le message d'information, la notice de confidentialité, les finalités déclarées, les durées de conservation et les journaux techniques. Les entreprises qui ont déjà structuré leur approche de protection des données personnelles partent avec une longueur d'avance, parce qu'elles savent relier le droit, l'UX et l'exploitation.
Ce que change le régime des systèmes à haut risque
Dès qu'un usage tombe dans le champ du haut risque, la question n'est plus “avons-nous informé l'utilisateur ?”. La vraie question devient “pouvons-nous démontrer que le système est utilisé dans les limites prévues, sous supervision adaptée, avec une documentation exploitable et des traces vérifiables ?”.
L'article 13 de l'AI Act impose alors un niveau de précision supérieur dans les instructions d'utilisation. Pour une DSI ou un directeur métier, cela se traduit par une checklist très concrète. Il faut pouvoir remettre aux équipes de déploiement une notice claire sur l'usage prévu, les limites connues, les prérequis techniques, les conditions de supervision humaine, les risques prévisibles, les niveaux de performance annoncés et les éléments à tracer. Si ces informations sont dispersées entre une slide commerciale, un wiki technique et quelques tickets Jira, la conformité sera difficile à défendre.
C'est souvent là que les projets se fragilisent. Les équipes juridiques rédigent une information correcte. Les équipes data documentent le modèle. Mais personne ne transforme ces exigences en consignes d'exploitation. Or c'est ce document intermédiaire qui évite les dérives de terrain. Qui peut valider une réponse sensible. Quand faut-il bloquer une action. Quels cas doivent partir vers un humain. Quels événements doivent être journalisés pour permettre une revue a posteriori.
Une documentation de conformité utile sert à l'exploitation quotidienne. Si elle n'aide pas un superviseur, un support niveau 2 ou un auditeur interne à comprendre ce qui s'est passé, elle reste incomplète.
Le sujet devient encore plus concret dans les flux internes. Un agent qui aide un back-office à traiter des dossiers, à résumer des pièces ou à proposer une action métier peut créer des gains réels, mais il augmente aussi l'exigence sur la traçabilité et la responsabilité opérationnelle. C'est précisément l'enjeu des agents IA pour les processus back-office, où chaque recommandation doit rester explicable, révisable et rattachée à un cadre d'usage défini.
Les briques techniques d'un agent IA transparent
Un agent conversationnel devient opaque pour une raison simple. L'équipe projet ne sait plus expliquer, en exploitation, pourquoi une réponse a été produite, sur quelles sources elle s'appuie, et à quel moment un humain doit reprendre la main. La transparence utile se joue donc dans les composants, les journaux, et les règles de contrôle. Pas dans une promesse de principe.
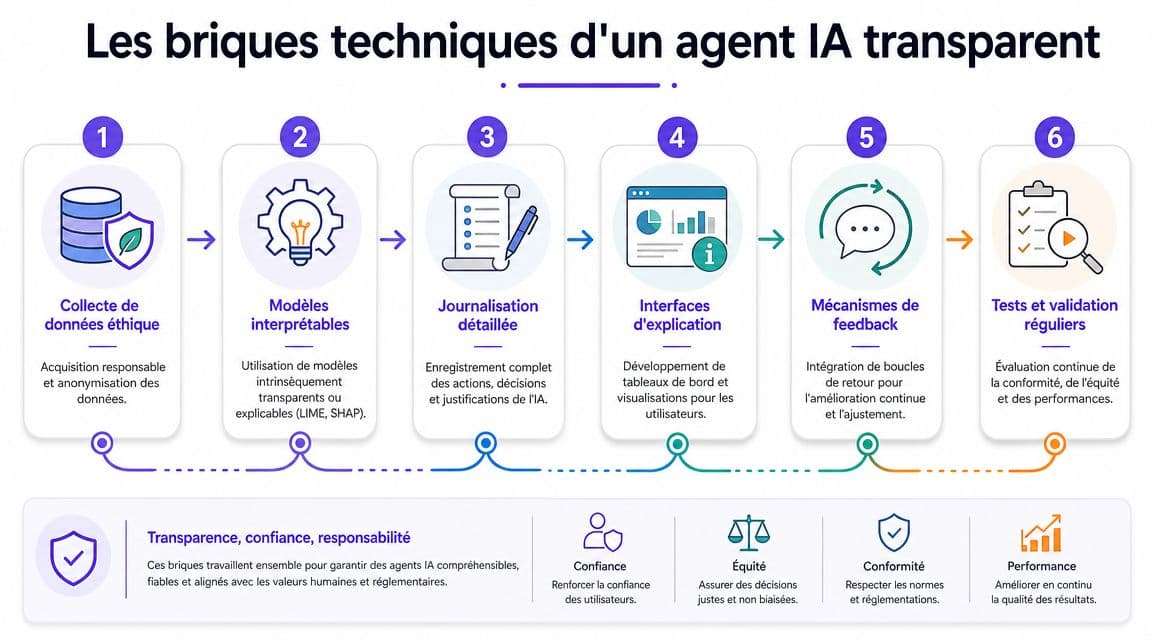
RAG, journalisation, supervision. Ce qui tient en production
La première brique, en pratique, est le RAG. Un agent qui va chercher l'information dans un corpus validé avant de générer une réponse se gouverne mieux qu'un LLM qui improvise sur une base trop large. Le gain n'est pas théorique. En audit interne, en traitement d'incident ou en revue métier, il devient possible de rattacher une réponse à un document, à une version de base documentaire et à une règle d'usage. Cela ne supprime ni les erreurs de récupération ni les biais de formulation, mais le système reste vérifiable.
La deuxième brique est la journalisation détaillée. Le cadre posé plus haut impose une information exploitable sur le fonctionnement du système. Sur le terrain, cela veut dire une chose. Une équipe support, un RSSI, un responsable conformité ou un métier doit pouvoir reconstituer le chemin complet d'une réponse sans lire le code source ni interroger trois prestataires.
Une journalisation utile enregistre au minimum :
-
Le contexte d'entrée
Canal, horodatage, profil ou segment utilisateur si pertinent, type de demande, règle de routage déclenchée. -
Les éléments ayant pesé dans la réponse
Documents récupérés, score ou ordre de pertinence si l'outil le fournit, version du prompt, paramètres du modèle, garde-fous activés, appel à une API métier. -
Le résultat produit
Réponse affichée, action déclenchée, niveau de confiance interne si disponible, blocage éventuel. -
La reprise humaine
Escalade, correction, validation, rejet, commentaire du superviseur.
Le point délicat est là. Journaliser plus ne veut pas toujours dire journaliser mieux. Dans un contexte RGPD, conserver l'intégralité des prompts, des pièces jointes et des données personnelles sans politique de minimisation crée un nouveau risque. La bonne approche consiste à séparer les logs d'exploitation, les traces de sécurité et les données utiles à l'amélioration, avec des durées de conservation et des droits d'accès distincts.
La troisième brique est la supervision humaine outillée. Une supervision crédible ne repose pas sur une boîte mail “en cas de problème”. Elle repose sur des seuils d'escalade, des files de revue, des rôles nommés et des délais de traitement. Pour un agent de relation client, les cas sensibles sont généralement connus dès le cadrage. Réclamations complexes, données personnelles, décision commerciale engageante, cas juridique, situation de vulnérabilité. Si ces cas ne sortent pas automatiquement du flux, la transparence affichée ne résistera pas à l'usage réel.
Les mauvais choix qui dégradent la traçabilité
L'opacité apparaît rarement à cause d'un seul composant. Elle vient d'une suite de raccourcis techniques et organisationnels.
| Mauvais réflexe | Effet réel |
|---|---|
| Brancher un LLM sur tout le contenu disponible | Le corpus devient impossible à qualifier et les réponses deviennent difficiles à justifier |
| Conserver des logs trop pauvres | L'équipe ne peut ni auditer un incident ni expliquer une action contestée |
| Mélanger réponse générée, règle métier et contenu validé | L'utilisateur et le superviseur ne distinguent plus ce qui a été calculé, imposé ou approuvé |
| Reporter les règles d'escalade à la phase d'après | Les erreurs s'accumulent avant d'être détectées et corrigées |
L’explicabilité doit rester orientée action. Une interface qui affiche vingt signaux, trois scores et une carte de chaleur n'aide personne si le superviseur ne sait pas quoi faire ensuite. Une bonne interface de transparence répond à quatre questions. Quelle source a été utilisée. Quelle règle a été appliquée. Quel niveau de risque est associé à la réponse. Qui peut corriger ou valider.
Un agent transparent ne montre pas tout. Il expose ce qu'il faut pour décider, corriger et prouver.
Dernier point souvent sous-estimé, l’orchestration. Un agent conversationnel en production combine presque toujours plusieurs briques. Recherche documentaire, LLM, règles métier, APIs, filtres de sécurité, routage humain, parfois plusieurs modèles selon le type de demande. Si ce chaînage n'est pas structuré, la transparence disparaît au premier incident. Des solutions d’agents IA orchestrés pour les usages métier permettent d'industrialiser cette chaîne avec une traçabilité exploitable, à condition de configurer dès le départ les journaux, les seuils d'escalade et les responsabilités d'exploitation.
Checklist de déploiement pour un agent IA conforme
Une checklist utile ne doit pas ressembler à une liste d'intentions. Elle doit aider une équipe projet à décider si l'agent peut passer au build, à la mise en production, puis à l'exploitation continue.
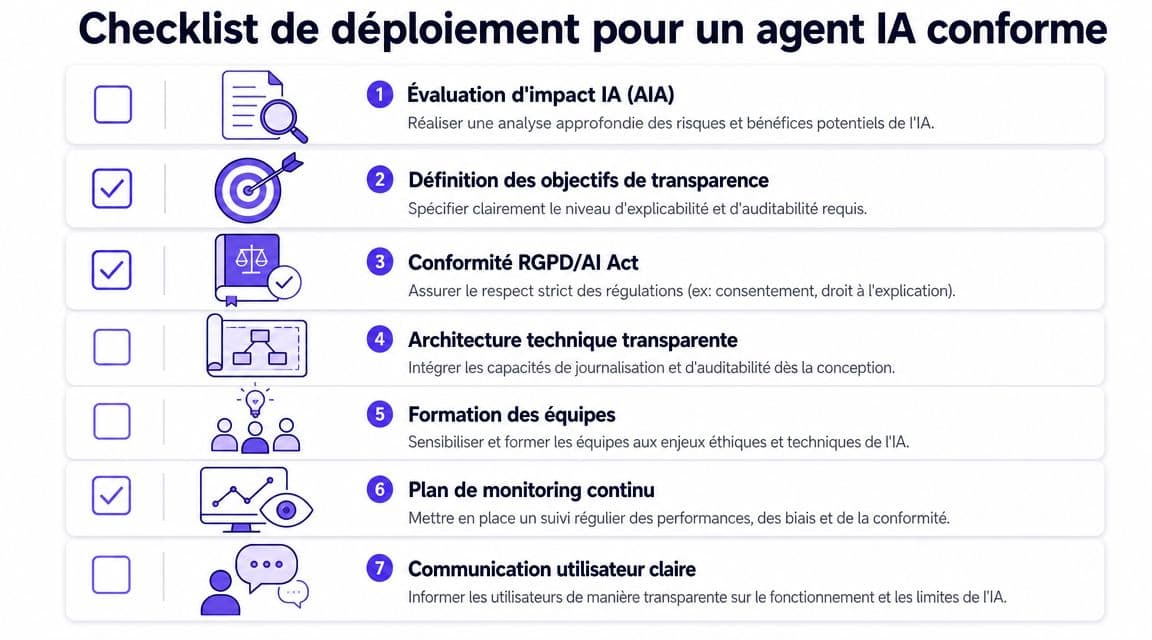
Avant le build
Commencez par le périmètre. Si l'équipe ne sait pas précisément quels cas d'usage l'agent traite, tout le reste sera flou.
-
Délimiter le périmètre métier
Lister les demandes autorisées, les demandes exclues, et les cas qui imposent une reprise humaine. -
Qualifier les données mobilisées
Identifier les sources internes, publiques et privées, puis définir qui les valide. -
Vérifier la traçabilité fournisseur
À partir du 2 août 2025, tout nouveau modèle d'IA à usage général commercialisé ou distribué dans l'UE devra être accompagné d'un résumé public des données d'entraînement, tandis que les modèles déjà sur le marché auront jusqu'au 2 août 2027 pour se mettre en conformité (calendrier et exigence documentaire). Si votre prestataire n'est pas capable de documenter ses sources à ce niveau, l'alerte doit remonter tout de suite.
Avant la mise en production
À ce stade, le plus important n'est pas de savoir si le bot “répond bien” dans une démo. Il faut savoir s'il répond de manière gouvernable.
-
Contrôler le message de transparence utilisateur
L'utilisateur est-il clairement informé qu'il échange avec une IA ? -
Tester les scénarios d'escalade
Quand l'agent hésite, quand il sort du périmètre, quand il touche un cas sensible, la bascule est-elle propre ? -
Valider la chaîne de preuve
Peut-on reconstituer une réponse, ses sources, les règles appliquées et l'éventuelle reprise humaine ? -
Former les équipes d'exploitation
Les superviseurs savent-ils corriger la base documentaire, traiter une contestation et analyser un log ?
Après le lancement
La transparence IA se dégrade vite si personne ne la pilote dans la durée. Les bases changent, les consignes évoluent, les usages dérivent.
-
Mettre en place une revue régulière
Revoir les erreurs, les escalades, les contournements et les demandes non couvertes. -
Versionner les changements
Toute évolution du corpus, des prompts système, des règles métier ou des workflows doit être historisée. -
Documenter les limites connues
Un agent conforme n'est pas un agent parfait. C'est un agent dont les limites sont connues, affichées et traitées.
Pour les équipes relation client, cette checklist devient beaucoup plus concrète quand elle est reliée à un vrai usage terrain, comme celui des agents IA pour le service client, où la conformité dépend autant du parcours visible par l'usager que des mécanismes invisibles côté exploitation.
La transparence en action dans la relation client
Avant, un chatbot opaque
Le scénario est classique. Un client pose une question sur une garantie, un remboursement ou un changement de contrat. Le bot répond de manière fluide, mais sans source, sans nuance et sans possibilité claire de faire reprendre le dossier. Quand la réponse surprend, la confiance tombe immédiatement.
Le problème n'est pas seulement que la réponse puisse être fausse. Le problème est que le client ne sait pas sur quoi elle repose, et que l'entreprise ne sait pas facilement comment la justifier après coup.
Après, un agent qui explique, source et escalade
Un agent plus transparent fonctionne autrement. Il annonce qu'il s'agit d'une interaction automatisée. Il répond à partir d'un référentiel identifié. Il explicite la base de sa réponse dans un langage simple. Et si la demande sort du cadre, il passe la main.
Exemple concret.
Un bot opaque dira : “Votre demande n'est pas éligible.”
Un agent transparent dira : “Je me base sur la clause applicable de votre contrat telle qu'elle figure dans notre référentiel. Si vous souhaitez, je peux transmettre votre dossier à un conseiller pour vérification.”
La différence est majeure. La seconde réponse ne prétend pas tout expliquer. Elle donne juste assez d'éléments pour rendre la décision intelligible et laisser une porte de sortie.
Une étude de Penn State va dans ce sens. Le besoin d'explication dépend de l'écart entre l'attente de l'utilisateur et le résultat produit. Quand le système répond comme attendu, beaucoup d'utilisateurs n'exigent pas une explication détaillée. Quand il déçoit ou surprend, ils demandent davantage de justification (travaux relayés par Penn State). C'est une leçon très utile en relation client. Il ne faut pas surcharger chaque interaction. Il faut prévoir des explications ciblées au moment où la confiance vacille.
En service client, la bonne transparence n'est pas maximale. Elle est contextuelle.
C'est pour cela que les dispositifs les plus efficaces combinent message clair, sourçage discret, reprise humaine et supervision métier. Dans les usages de relation client assistée par agents IA, la transparence ne ralentit pas forcément le parcours. Bien pensée, elle réduit les incompréhensions, simplifie l'audit et protège la marque quand l'agent atteint ses limites.
Si vous devez cadrer un projet d'agent conversationnel avec des exigences de conformité, de traçabilité et de supervision humaine, Webotit.ai propose une plateforme d'IA conversationnelle conçue pour des déploiements SaaS ou on-premise, avec RAG, journalisation, contrôles métiers et cadre RGPD natif. C'est typiquement le type d'approche à évaluer quand vous voulez transformer la transparence IA en dispositif réellement exploitable par la DSI, le métier et la relation client.