Maîtrisez le disaster recovery : Guide essentiel 2026
Maîtrisez le disaster recovery : Guide essentiel 2026
Découvrez notre guide complet sur le disaster recovery : définition, RTO/RPO, stratégies, planification et conformité RGPD/SecNumCloud.
Parler de ce sujet avec Webotit
Lundi, 8 h 12. Votre équipe e-commerce ouvre les tableaux de bord et voit d'abord un détail étrange. Les commandes ne remontent plus. À 8 h 19, le site devient inaccessible. À 8 h 27, le centre de contact reçoit une vague d'appels, puis d'emails, puis de messages sur les réseaux sociaux. Les équipes techniques cherchent la cause. Les équipes métier, elles, cherchent une réponse à une autre question. Comment continuer à servir les clients pendant que les systèmes vacillent ?
C'est souvent à ce moment-là que le disaster recovery cesse d'être un sujet d'infrastructure. Il devient un sujet de revenus, de confiance et de gouvernance. Une panne majeure ne coupe pas seulement des serveurs. Elle interrompt des parcours d'achat, retarde des remboursements, bloque des conseillers, désorganise les opérations internes et expose la direction à une crise de réputation en temps réel. Le client, lui, ne distingue ni la base de données, ni le cluster, ni la réplication. Il retient une seule chose. La marque était-elle joignable, claire et fiable au moment où il en avait besoin ?
Les directions générales qui traversent bien ce type d'événement ont un point commun. Elles ont traité la reprise après sinistre comme une capacité stratégique, pas comme une ligne de coût à réduire. Elles savent qu'une architecture solide ne suffit pas si personne ne peut informer les clients, rediriger les flux, prioriser les activités critiques et enclencher les bonnes décisions sans friction. C'est exactement là que la résilience opérationnelle prend de la valeur concrète, à la fois pour l'IT et pour l'expérience client.
Dans des environnements où les interactions doivent rester fluides sur le web, la voix et l'email, l'enjeu n'est plus seulement de redémarrer vite. Il faut aussi préserver une continuité de service perceptible. Des plateformes comme les solutions d'automatisation conversationnelle montrent pourquoi ce sujet dépasse désormais le périmètre traditionnel du PRA.
Introduction quand l'impensable paralyse votre activité
Le scénario le plus dangereux n'est pas toujours le plus spectaculaire. Ce n'est pas forcément l'incendie d'un datacentre ou l'attaque qui fait la une. C'est souvent l'incident banal en apparence qui révèle une dépendance oubliée. Un service d'identité tombe. Une intégration de paiement ne répond plus. Un stockage partagé se corrompt. En quelques minutes, des fonctions entières de l'entreprise s'arrêtent sans que personne n'ait encore une vision complète de la chaîne d'impact.
Pour un comité exécutif, la vraie question n'est pas seulement “combien de temps pour redémarrer ?”. Elle est double. Quelles capacités doivent rester visibles pour le client pendant la panne, et quelles décisions doivent être prises sans attendre un diagnostic parfait ? Une entreprise qui sait commander une bascule technique mais pas orchestrer sa communication crée elle-même une seconde crise. La panne IT devient une panne de relation client.
La panne visible n'est que la moitié du problème
Prenons un exemple simple. Une enseigne de retail subit une indisponibilité sur son site marchand un jour de forte activité. L'équipe infrastructure travaille sur la restauration. Pendant ce temps, les conseillers n'ont pas de script commun, la page de statut n'est pas à jour, les emails de confirmation partent avec retard et les clients n'obtiennent aucune réponse cohérente selon le canal utilisé. Techniquement, l'entreprise “gère”. Commercialement, elle détériore sa promesse de service.
Une organisation résiliente ne juge pas seulement sa capacité à restaurer un système. Elle juge sa capacité à rester crédible pendant la restauration.
Cette distinction change la manière d'investir. Si vous regardez le disaster recovery uniquement comme une police d'assurance technique, vous aurez tendance à arbitrer au plus bas coût. Si vous le considérez comme un levier de continuité des revenus et de protection de l'expérience client, vous définirez des priorités différentes. Certaines applications peuvent attendre. D'autres ne doivent jamais disparaître du point de vue du client, même brièvement.
Un sujet de direction générale, pas uniquement de DSI
Le DR n'appartient plus à un silo. La finance doit comprendre les compromis entre coût d'architecture et tolérance métier à l'arrêt. Le juridique et la conformité doivent exiger des preuves de test. Les directions service client doivent préparer des mécanismes de réponse dégradée. Les métiers doivent accepter qu'on ne protège pas tout au même niveau.
Les entreprises qui avancent bien sur ce terrain ont une approche plus adulte de la résilience. Elles classent les activités critiques, identifient les dépendances, préparent des scénarios de communication et répètent les gestes de crise. Elles savent aussi que la vitesse de réponse ne dépend pas seulement des ingénieurs. Elle dépend de la qualité des décisions prises dans les premières minutes.
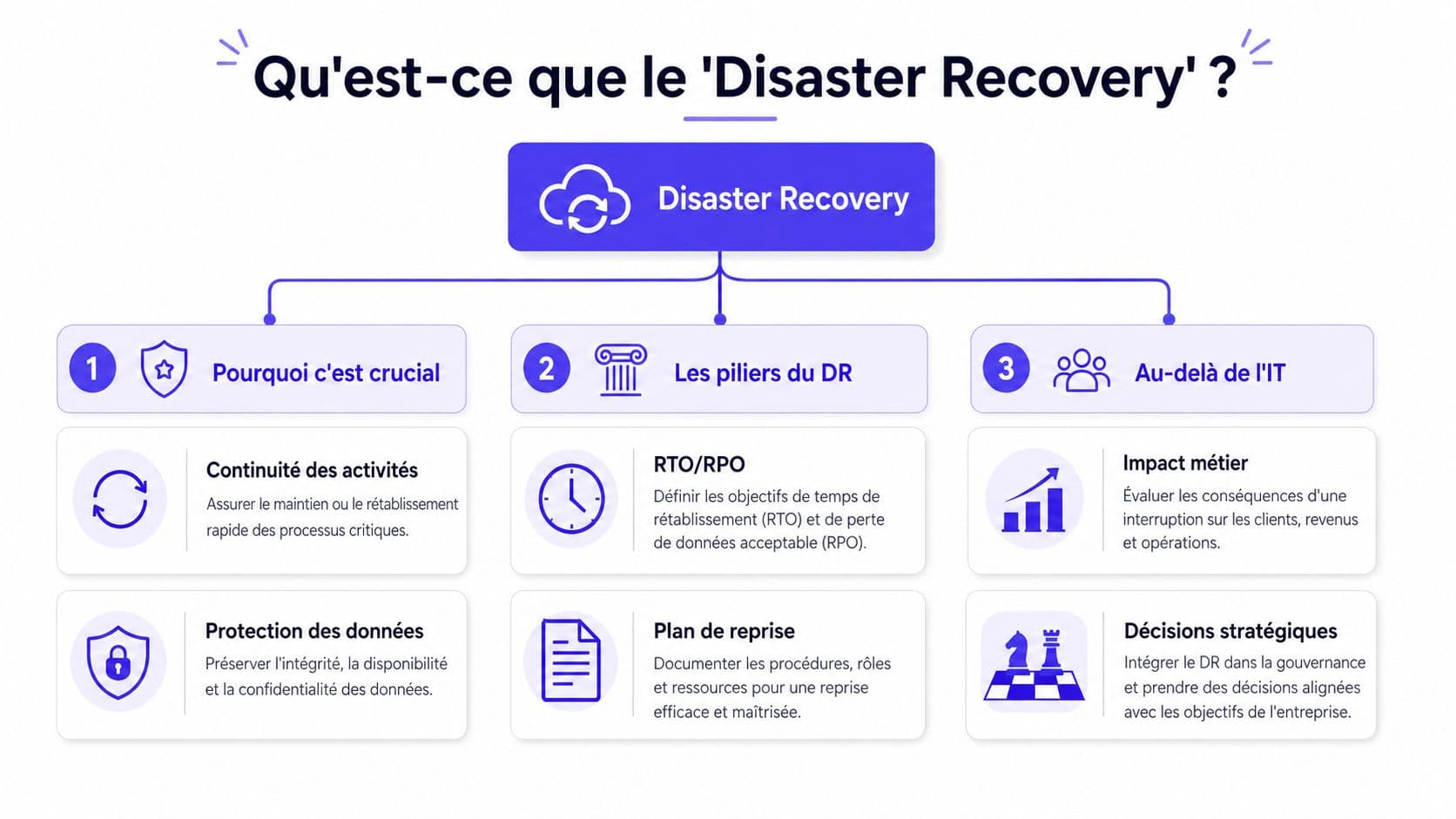
Définir le Disaster Recovery au-delà du jargon IT
Le disaster recovery désigne l'ensemble des moyens techniques et organisationnels qui permettent de restaurer des systèmes, des applications et des données après une interruption majeure. Dit autrement, ce n'est pas l'art de faire des copies. C'est l'art de remettre l'entreprise en capacité d'opérer dans des conditions acceptables après un choc.
La sauvegarde n'est pas la reprise
La confusion la plus fréquente tient en une phrase. “Nous avons des sauvegardes, donc nous sommes couverts.” C'est faux dans de nombreux cas.
La sauvegarde ressemble à une copie de vos documents importants placée dans un coffre. Si votre bureau brûle, vous avez toujours l'information. Mais vous n'avez plus de bureaux, plus de téléphonie, plus de postes de travail, plus d'accès applicatifs, plus de procédures coordonnées pour reprendre l'activité. Le disaster recovery, lui, répond à une question plus dure. Comment reconstruire un environnement opérationnel, dans quel ordre, avec quelles dépendances et sous quelle gouvernance ?
Voici la différence concrète :
- Sauvegarde des données : elle protège l'information contre la perte ou la corruption.
- Plan de reprise : il définit comment rétablir les composants techniques nécessaires.
- Organisation de crise : elle précise qui décide, qui exécute et qui informe.
- Validation métier : elle confirme que le service restauré est réellement exploitable.
Une restauration de base de données n'a aucune valeur si l'application n'accède plus au service d'authentification. Un portail client revenu en ligne n'aide personne si le paiement, l'email transactionnel ou la logistique restent indisponibles.
Le DR comme pilier de la continuité d'activité
La continuité d'activité est plus large. Elle cherche à maintenir les services essentiels, même en mode dégradé. Le disaster recovery constitue son pilier technologique. Il remet en état les briques numériques sur lesquelles reposent vos processus, vos équipes et vos interactions clients.
Cette distinction aide beaucoup en comité de direction :
| Notion | Périmètre | Question principale |
|---|---|---|
| Disaster recovery | Systèmes, applications, données, infrastructure | Comment restaurer l'IT dans un délai acceptable ? |
| Continuité d'activité | Personnes, processus, fournisseurs, sites, communication | Comment continuer à servir malgré la perturbation ? |
Règle pratique : si votre plan ne précise que des actions techniques, vous avez un début de DR. Vous n'avez pas encore une vraie continuité d'activité.
Un bon DR ne sert donc pas uniquement l'IT. Il protège la capacité à traiter une commande, répondre à un assuré, orienter un patient, reprendre un dossier ou rassurer un client. Pour un dirigeant, c'est la différence entre “nos systèmes ont été rétablis” et “nos opérations ont réellement repris”.
Les métriques qui pilotent votre stratégie RTO et RPO
Le débat devient sérieux quand on introduit deux métriques simples. RTO et RPO. Tant qu'elles ne sont pas définies application par application, la résilience reste un concept abstrait. Dès qu'elles sont arbitrées, le disaster recovery devient un sujet de niveau de service, donc de budget, donc de gouvernance.
RTO et RPO traduits en langage de direction
Le RTO correspond au délai maximal acceptable pour remettre un service en fonctionnement. Le RPO correspond à la quantité maximale de données que l'entreprise accepte de perdre entre le dernier état récupérable et l'incident.
Vu d'un dirigeant, la différence est essentielle. Le RTO parle du temps d'interruption. Le RPO parle de mémoire perdue.
Prenons trois situations très différentes :
- Site e-commerce : l'arrêt est visible immédiatement. Le besoin porte souvent sur une reprise très rapide et sur une perte de données minimale, car chaque panier, paiement ou confirmation manqué affecte la relation client.
- Outil de reporting interne : une interruption peut être pénible sans être bloquante. Le métier peut tolérer un délai de reprise plus large et une restauration sur un point de sauvegarde moins rapproché.
- Base de connaissance du service client : si elle disparaît, les conseillers rallongent leurs temps de traitement et la qualité de réponse se dégrade. La criticité n'est pas toujours financière à la minute, mais elle devient vite opérationnelle et réputationnelle.
Cela impose un changement de posture. L'IT ne devrait pas définir seule les cibles. Chaque direction métier doit dire ce qu'elle accepte réellement. Beaucoup découvrent alors qu'elles exigent implicitement une résilience “haut de gamme” sans avoir validé le niveau d'investissement qu'elle implique.
Classer les applications selon leur impact réel
Une méthode utile consiste à classer les applications non par prestige interne, mais par conséquence d'indisponibilité. Voici un cadre simple.
| Type d'application | Criticité métier | RTO typique | RPO typique |
|---|---|---|---|
| Site transactionnel client | Très élevée | Très court | Très faible perte admissible |
| CRM centre de contact | Élevée | Court | Faible perte admissible |
| ERP financier | Élevée | Modéré à court selon la période | Faible à modérée selon les flux |
| Outil RH interne | Moyenne | Modéré | Modéré |
| Reporting décisionnel | Variable | Plus large | Plus large |
Ce tableau n'est pas une norme. C'est un point de départ pour la discussion.
Les arbitrages les plus intelligents apparaissent quand vous regardez aussi les dépendances cachées. Une application peu visible peut bloquer une chaîne critique. Un service d'authentification, un annuaire, une passerelle API ou une file de messages n'apparaissent pas toujours en tête de liste métier, mais leur indisponibilité peut immobiliser plusieurs applications à la fois.
Quelques questions aident à sortir des généralités :
- Le client voit-il la panne directement ?
- Une transaction en cours peut-elle être perdue sans impact juridique ou commercial majeur ?
- Existe-t-il un mode manuel ou dégradé crédible ?
- L'application supporte-t-elle d'autres applications critiques ?
- Qui valide que le service est “revenu”, l'IT ou le métier ?
Quand le métier dit “il faut redémarrer vite”, demandez “vite pour qui, et avec quelle perte de données acceptable ?”. C'est souvent là que naît la vraie priorisation.
Le point moins évident concerne le ROI. Définir un RTO et un RPO plus stricts n'est pas toujours rationnel. Surprotéger un service peu critique immobilise du budget, de l'attention et de la complexité technique qui manquent ensuite là où la panne serait réellement destructrice. À l'inverse, sous-protéger une fonction client visible est une économie trompeuse. Le coût évité côté infrastructure réapparaît ensuite côté support, churn, réputation et charge opérationnelle.
Architectures et stratégies de reprise après sinistre
Une fois les objectifs de reprise clarifiés, le choix d'architecture devient un arbitrage assumé entre vitesse, coût et complexité. Il n'existe pas de “meilleure” stratégie universelle. Il existe un niveau de préparation cohérent avec la valeur du service à protéger et avec l'appétence de l'entreprise pour le risque.

Quatre niveaux d'investissement, quatre promesses de reprise
La première famille, sauvegarde et restauration, reste la base. On sauvegarde régulièrement, puis on reconstruit lors d'un incident. C'est souvent suffisant pour des applications de support ou des archives. En revanche, les dépendances doivent être bien documentées. Restaurer des données sans restaurer la configuration, les secrets, les intégrations et les versions applicatives vous expose à une reprise lente et fragile.
Le cold site ajoute un site ou un environnement de secours prêt à être activé, mais peu ou pas pré-équipé au niveau applicatif. Le coût est plus contenu, mais la reprise demande du temps et une excellente discipline d'exécution. Cette approche séduit parfois les directions financières parce qu'elle limite l'immobilisation de ressources. Elle déçoit souvent lorsqu'un incident réel exige une vitesse de bascule que l'organisation n'a jamais réellement répétée.
Le warm site représente un compromis plus mature. Une partie de l'environnement de secours est prépositionnée. Les données, configurations ou services essentiels sont synchronisés à un niveau suffisant pour accélérer la remise en route. Le coût monte, tout comme l'effort d'exploitation. En échange, la reprise devient plus réaliste pour des applications client ou métiers importantes.
Le hot site, ou architecture proche de l'actif/passif avancé ou de l'actif/actif, cherche une reprise quasi immédiate. Il suppose une réplication soutenue, une supervision serrée et des procédures de bascule/failback très rigoureuses. C'est la bonne réponse pour les activités où l'indisponibilité est très peu tolérable, mais c'est aussi l'option la plus exigeante à opérer.
Le bon choix dépend moins de la technologie que de l'arbitrage métier
La comparaison utile n'est pas “quelle solution est la plus moderne ?”. Elle est plutôt “quel niveau de coût et de complexité sommes-nous prêts à accepter pour respecter les cibles validées avec le métier ?”.
| Stratégie | Coût relatif | Complexité | Vitesse de reprise |
|---|---|---|---|
| Backup & Restore | Faible | Faible à modérée | Lente |
| Cold Site | Faible à modérée | Modérée | Lente à moyenne |
| Warm Site | Modérée à élevée | Élevée | Rapide |
| Hot Site / Actif-Actif | Élevée à très élevée | Très élevée | Très rapide |
Un point est souvent sous-estimé par les directions. Plus on réduit le délai de reprise, plus on transfère de la charge vers l'exploitation quotidienne. Il faut maintenir la cohérence entre sites, tester plus souvent, gérer les écarts de version, surveiller les réplications, automatiser les séquences et sécuriser les dépendances externes. Le budget n'achète pas seulement de la capacité de secours. Il achète aussi une discipline d'exploitation.
Pour les organisations fortement interconnectées, l'orchestration joue ici un rôle majeur. La reprise ne consiste pas à allumer des briques indépendantes. Il faut respecter l'ordre, vérifier les prérequis, notifier les bonnes équipes, confirmer les contrôles et informer les parties prenantes. C'est pourquoi des dispositifs d’agents IA back-office pour l'orchestration opérationnelle deviennent intéressants dans des environnements complexes, en particulier lorsque les procédures comportent plusieurs acteurs, plusieurs systèmes et plusieurs canaux de notification.
Une architecture chère mais mal orchestrée peut échouer plus vite qu'une architecture plus simple et mieux répétée.
Autre angle stratégique. Le disaster recovery n'a pas besoin d'être uniforme. Une entreprise mature mélange souvent les approches. Elle réserve le niveau de protection le plus élevé aux parcours clients critiques, adopte un compromis sur les applications métiers centrales et conserve un modèle de restauration plus classique pour les services à plus faible impact. Cette hétérogénéité n'est pas un défaut. C'est souvent le signe d'une gouvernance rationnelle.
Construire et tester son Plan de Reprise d'Activité (PRA)
Un PRA utile ne ressemble pas à un classeur oublié dans un espace documentaire. C'est un dispositif exécutable, compréhensible sous pression et capable de guider des équipes qui n'auront ni temps, ni sérénité, ni information parfaite au moment du sinistre.
Ce qu'un PRA exécutable doit contenir
Le plan doit d'abord préciser les conditions de déclenchement. Qui constate l'incident ? Qui peut déclarer l'état de crise ? Qui a l'autorité pour ordonner une bascule, suspendre un service ou activer une communication client ? Si ces points ne sont pas clairs, les premières minutes se perdent en validations implicites.
Ensuite, le PRA doit décrire les éléments suivants :
- Le périmètre prioritaire : quelles applications, quels flux, quels processus doivent être traités en premier.
- Les dépendances critiques : identité, réseau, API, fichiers, outils de supervision, fournisseurs externes.
- Les rôles nommés : responsables techniques, décideur métier, communication, juridique, service client, astreinte.
- Les runbooks : étapes de restauration, contrôles, critères de succès, retour arrière.
- Les messages prêts à l'emploi : communication interne, clients, partenaires, direction.
- Les preuves attendues : journaux, comptes rendus, résultats de tests, validations métier.
Le point souvent négligé concerne la relation client. Beaucoup de PRA savent relancer des machines. Peu savent répondre proprement à un afflux de demandes pendant la panne. Or, la qualité de cette réponse influence fortement la perception de maîtrise. Une base de connaissance IA pour le service client peut aider à centraliser les scénarios, les consignes et les réponses validées, afin d'éviter les messages contradictoires entre équipes, canaux et horaires.
Tester pour apprendre, pas pour cocher une case
Un PRA non testé est un PRA théorique. En situation réelle, la théorie échoue souvent sur des détails concrets. Un contact n'est plus à jour. Une dépendance tierce n'avait pas été identifiée. Une procédure suppose un accès qui n'existe plus. Une équipe attend une validation d'une autre équipe sans le savoir. La seule manière de révéler ces points est le test.
Les formats de test doivent varier :
-
Exercice sur table
Les équipes rejouent un scénario, discutent les décisions et vérifient les responsabilités. Ce format expose bien les ambiguïtés de gouvernance. -
Test technique partiel
On restaure un composant, une application ou une base dans un environnement contrôlé. Ce format met en lumière les défauts de documentation et les écarts de configuration. -
Bascule encadrée
On exécute tout ou partie du mécanisme de reprise dans des conditions proches du réel. C'est le test le plus exigeant et souvent le plus instructif.
Le test n'a pas pour fonction de rassurer la direction. Il a pour fonction de faire remonter ce qui cassera sinon au pire moment.
Les environnements réglementés doivent aller plus loin. La conformité ne s'arrête pas à la protection des données. Elle implique aussi la capacité à démontrer que les données et services essentiels restent disponibles ou restaurables de manière maîtrisée. Dans des cadres comme le RGPD ou des environnements alignés sur des exigences de type SecNumCloud, la documentation, la traçabilité, la preuve de test et la maîtrise des accès deviennent des éléments de gouvernance, pas de simples annexes techniques.
Pour les dirigeants, la meilleure question n'est pas “avons-nous un PRA ?”. C'est “quand l'avons-nous testé pour la dernière fois dans un scénario réaliste, et qu'avons-nous corrigé ensuite ?”. Si la réponse est floue, le niveau réel de préparation l'est aussi.
Le futur du DR: automatiser la réponse avec les Agents IA
Le maillon faible d'une crise n'est pas toujours l'infrastructure. C'est souvent la charge cognitive des équipes. Sous stress, même des procédures correctes sont mal exécutées. Des notifications partent trop tard. Des messages divergent selon les canaux. Des étapes sont faites dans le mauvais ordre. C'est ici que les AI Agents apportent une rupture nette par rapport aux approches plus anciennes de type RPA.
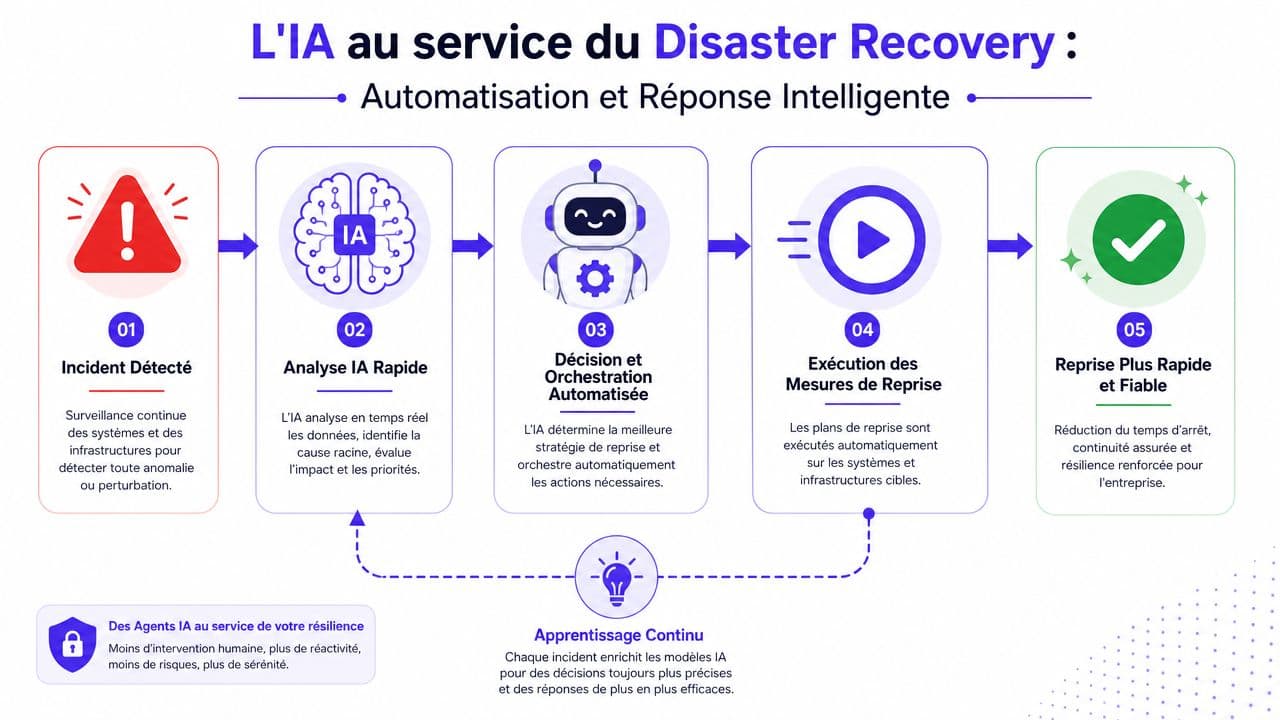
L'agent IA comme couche de coordination en temps de crise
Un agent IA n'est pas un simple bot qui attend une question. Il peut surveiller des signaux, interpréter un contexte, déclencher des séquences et assister la prise de décision dans un cadre gouverné. Dans un dispositif de disaster recovery, cela change plusieurs choses.
D'abord, l'agent peut agréger les alertes issues de la supervision, reconnaître un scénario connu et lancer les premiers workflows. Notification des astreintes. Création d'un canal de crise. Publication d'un message validé sur une page de statut. Distribution d'un brief au service client. Ouverture d'une checklist de reprise. Ce type d'orchestration réduit la latence entre détection et action.
Ensuite, l'agent peut standardiser la communication. Au lieu de laisser chaque équipe improviser, il diffuse des informations cohérentes selon le rôle du destinataire. Un dirigeant n'a pas besoin du même niveau de détail qu'un client ou qu'un exploitant. Cette segmentation améliore à la fois la clarté et la discipline de crise.
Pour les organisations qui cherchent à intégrer l'IA dans votre business, le DR est un terrain particulièrement pertinent. La valeur n'y vient pas d'un effet de mode. Elle vient d'une exécution plus rapide, plus traçable et moins dépendante des réflexes individuels.
Un aperçu concret des usages possibles en environnement opérationnel se trouve dans les agents IA d'orchestration et d'automatisation.
Pourquoi les AI Agents changent aussi l'expérience client
La plupart des stratégies de reprise restent centrées sur les systèmes. Or le client vit surtout la qualité de la communication pendant l'incident. S'il obtient une information claire, cohérente et actualisée, la panne reste grave mais maîtrisée. S'il fait face au silence, à l'attente ou aux contradictions, la confiance chute plus vite que la disponibilité technique.
C'est là que les agents IA surpassent une logique purement NLP ou une automatisation rigide. We use LLM over NLP, we use AI Agents over RPA. Cette approche permet de traiter des demandes formulées librement, d'exploiter une base de connaissance contextualisée et de décider de l'escalade vers un humain lorsque la situation l'exige.
Deux cas d'usage sont particulièrement solides :
- Communication de crise multicanale : un callbot, un chatbot ou un mailbot peut absorber une large part des sollicitations répétitives, informer sur l'état du service, orienter vers des alternatives et réserver les cas sensibles aux équipes humaines.
- Exécution coordonnée du PRA : l'agent peut piloter des séquences, demander des confirmations, relancer les propriétaires d'étapes et maintenir un journal d'actions exploitable après l'incident.
La vidéo ci-dessous illustre bien la logique d'automatisation intelligente appliquée aux opérations.
L'insight le plus utile pour un dirigeant tient en ceci. L'IA ne remplace pas le PRA. Elle transforme son exécution. Elle retire de la friction là où les minutes comptent le plus, notamment dans la coordination et la communication. Et dans une crise, c'est souvent ce qui sépare une reprise techniquement correcte d'une reprise perçue comme fiable par les clients.
Votre checklist pour une résilience opérationnelle en 2026
Un programme de disaster recovery mature se reconnaît moins à son vocabulaire qu'à ses habitudes. Les organisations les plus solides révisent, testent, simplifient et mettent à jour en continu. Celles qui restent vulnérables ont souvent un document, parfois une sauvegarde, mais rarement une capacité de reprise réellement pilotée.
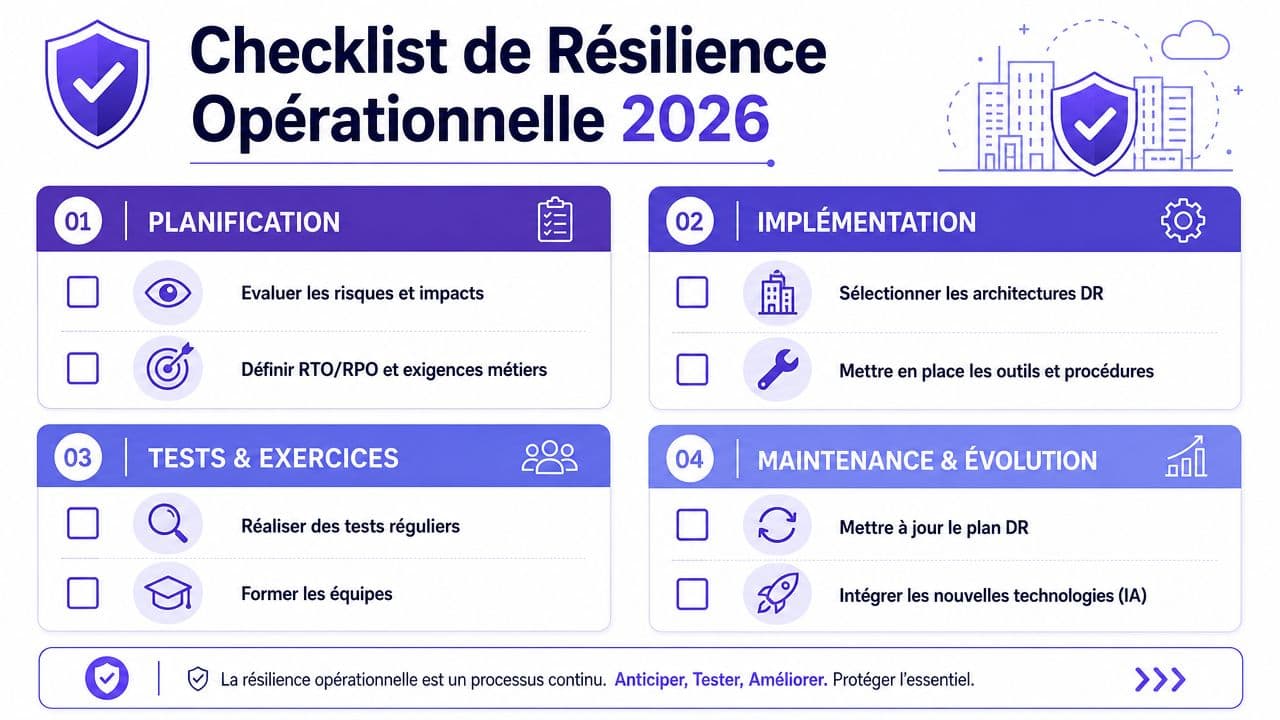
Les questions à poser en comité de direction
Commencez par un auto-diagnostic sobre. Si plusieurs réponses restent incertaines, la priorité n'est pas d'acheter plus de technologie. La priorité est de clarifier vos arbitrages.
- Criticité métier : les applications critiques sont-elles classées selon leur impact client, opérationnel, réglementaire et réputationnel ?
- Cibles de reprise : les couples RTO/RPO sont-ils validés par les métiers, pas seulement proposés par l'IT ?
- Dépendances : connaissez-vous les services invisibles qui peuvent immobiliser plusieurs applications à la fois ?
- Communication de crise : les messages destinés aux clients, aux partenaires et aux collaborateurs sont-ils prêts et gouvernés ?
- Capacité dégradée : savez-vous encore vendre, répondre ou traiter un dossier en mode dégradé ?
- Preuve de maîtrise : pouvez-vous démontrer qu'un test récent a produit des enseignements et des corrections ?
Si votre PRA dépend de quelques personnes clés qui “savent comment faire”, votre résilience dépend encore trop de la mémoire informelle.
Ajoutez ensuite une question souvent oubliée. Quels canaux restent actifs quand vos systèmes cœur sont perturbés ? Beaucoup d'entreprises pensent continuité de service, mais pas continuité d'information. Pourtant, dans une crise, la disponibilité d'un canal de réponse simple et fiable change fortement la perception de contrôle.
Un dispositif comme un mailbot de réponse aux emails peut, par exemple, jouer un rôle utile dans cette continuité d'information, à condition d'être intégré à une gouvernance de crise claire et à des contenus validés.
Une feuille de route simple pour passer à l'action
Si votre maturité est encore hétérogène, inutile de viser d'emblée une architecture maximale partout. Une progression réaliste fonctionne mieux.
-
Cartographier les services critiques
Partez des parcours clients et des obligations métier, puis remontez vers les applications et dépendances. -
Valider les arbitrages de reprise
Décidez explicitement ce qui doit repartir très vite, ce qui peut attendre et ce qui peut basculer en mode dégradé. -
Choisir les architectures adaptées
N'appliquez pas le même niveau de protection à tout. Réservez la sophistication là où elle protège vraiment du risque. -
Formaliser les rôles et la communication
Évitez les crises où tout le monde travaille mais personne ne décide, ou pire, tout le monde communique différemment. -
Tester et corriger
Chaque exercice doit produire des écarts, des décisions et des mises à jour. -
Automatiser les gestes répétitifs
Là où des notifications, vérifications et réponses se répètent, l'automatisation intelligente réduit le risque d'erreur.
La résilience opérationnelle n'est pas un projet figé. C'est une discipline de management. Elle oblige la direction à assumer ses priorités, l'IT à rendre les compromis visibles, et les métiers à définir ce qu'ils entendent réellement par “service disponible”. C'est aussi l'un des rares sujets où l'excellence technique et l'expérience client se rejoignent directement.
Webotit.ai aide les entreprises à rendre cette résilience concrète grâce à des agents IA, chatbots, callbots et mailbots capables d'automatiser la communication de crise, l'orchestration opérationnelle et la continuité de service sur plusieurs canaux. Si vous voulez structurer votre démarche de disaster recovery sans transformer le sujet en usine à gaz, découvrez Webotit.ai.