Résilience opérationnelle: votre guide complet 2026
Résilience opérationnelle: votre guide complet 2026
Découvrez comment bâtir votre stratégie de résilience opérationnelle. Guide 2026 sur DORA, IA, gouvernance et feuille de route.
Parler de ce sujet avec Webotit
Les entreprises parlent encore trop souvent de la résilience comme d'un sujet de secours, presque administratif. C'est une erreur de cadrage. En 2026, une étude indique que les interruptions de service non planifiées coûtent en moyenne 9 000 € par minute aux grandes entreprises, avec un effet sur la confiance client qui peut durer jusqu'à 12 mois après l'incident (étude 2026 sur le coût des interruptions). À ce niveau, la résilience opérationnelle n'est plus un appendice du PCA. C'est un sujet de revenu, de réputation et de continuité commerciale.
Le problème n'est pas seulement la panne. C'est la combinaison d'une dépendance forte aux plateformes, aux prestataires, aux API, au cloud, aux centres de contact et aux parcours digitaux. Un incident technique, un tiers défaillant, une cyberattaque ou une saturation du service client peuvent casser l'expérience de bout en bout. Le client, lui, ne distingue jamais la cause. Il retient seulement que l'entreprise n'a pas tenu sa promesse.
Les organisations les plus avancées ne cherchent plus uniquement à redémarrer vite. Elles cherchent à continuer à délivrer une valeur acceptable pendant la turbulence, puis à apprendre plus vite que leurs concurrents. C'est là que la résilience devient un actif stratégique. Pour beaucoup d'équipes, cela suppose de revoir l'architecture, la gouvernance et les mécanismes de relation client, y compris les dispositifs d’automatisation des opérations et interactions critiques.
Introduction La nouvelle réalité des disruptions
La disruption n'est plus un événement rare. C'est le contexte normal de fonctionnement. Les entreprises opèrent dans des chaînes de dépendance longues, avec des parcours clients distribués entre systèmes internes, outils SaaS, fournisseurs externes et canaux de contact multiples. Dans cet environnement, la panne franche n'est qu'un scénario parmi d'autres. Le mode dégradé durable est souvent plus fréquent, et parfois plus dangereux.
Le vieux réflexe consiste à traiter la résilience comme un dossier IT. On documente un plan, on archive des procédures, on vérifie la sauvegarde, puis on passe à autre chose. Cette logique rassure en comité. Elle protège mal sur le terrain. Lors d'un incident réel, les difficultés viennent rarement d'un seul composant. Elles viennent des interfaces entre équipes, de la dépendance à un tiers, de la confusion dans la communication client, ou d'un afflux de demandes que l'organisation ne sait pas absorber.
Passer de la reprise à l'absorption
Une entreprise résiliente ne promet pas l'absence de rupture. Elle s'organise pour éviter l'effet domino. Cela change la question de départ. Au lieu de demander “comment redémarrer ?”, il faut demander “comment continuer à servir correctement, même avec des contraintes fortes ?”.
Règle pratique: un service critique n'est pas seulement celui qui génère du chiffre d'affaires. C'est aussi celui dont l'indisponibilité dégrade immédiatement la confiance, le support, la conformité ou la capacité à expliquer la situation au client.
Les PCA classiques restent utiles. Mais seuls, ils sont devenus insuffisants. Ils ont été conçus pour des scénarios de reprise relativement linéaires. Or les incidents actuels sont interconnectés. Une attaque peut immobiliser des outils internes tout en saturant les demandes entrantes. Une panne chez un fournisseur peut bloquer une fonction métier tout en rendant les équipes incapables d'informer les clients.
Les piliers qui tiennent dans la durée
La résilience opérationnelle devient stratégique quand elle aligne trois niveaux en même temps :
- Le niveau business. Quels services doivent continuer, même en qualité réduite.
- Le niveau opérationnel. Qui décide, qui exécute, qui informe, qui escalade.
- Le niveau technologique. Quels systèmes, intégrations et canaux supportent ce mode de continuité.
Les entreprises qui y arrivent mieux ont une lecture plus mature du sujet. Elles considèrent la résilience non comme une dépense de précaution, mais comme une capacité concurrentielle. Quand un incident touche plusieurs acteurs d'un marché, celui qui informe vite, absorbe le pic de demandes et maintient un service lisible prend un avantage immédiat sur la relation client.
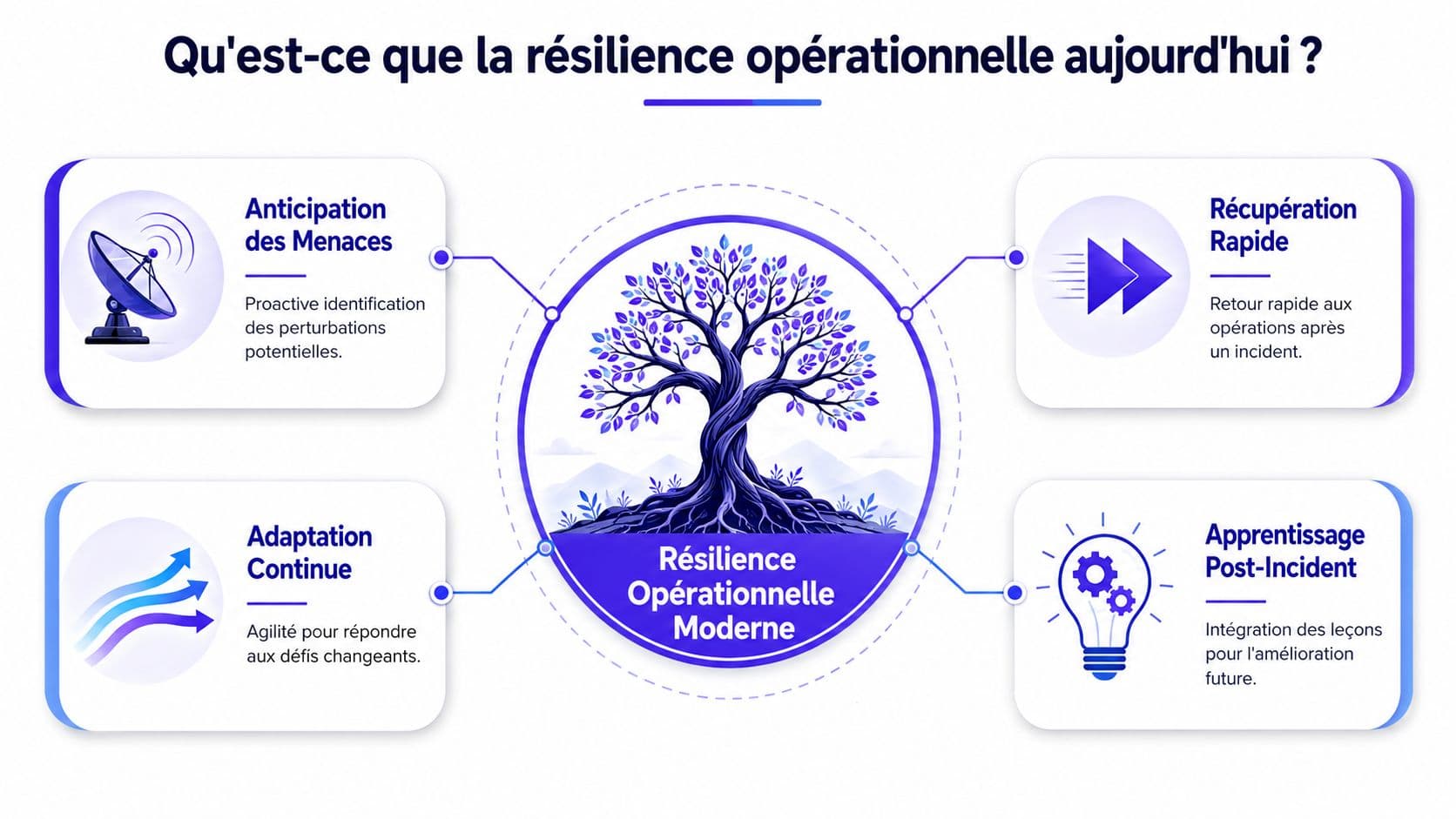
Qu'est-ce que la résilience opérationnelle aujourd'hui
La meilleure définition n'est pas “survivre à une crise”. C'est continuer à délivrer de la valeur malgré les turbulences. Cette nuance compte. Elle fait sortir la résilience opérationnelle du seul registre technique et l'installe au cœur de la promesse client.
Passer de la reprise à l'absorption
Le BCM traditionnel agit souvent comme une trousse de premiers secours. Il sert quand l'accident est là. La résilience opérationnelle moderne ressemble davantage à un système immunitaire. Elle détecte, encaisse, compense, récupère et apprend.
Cette différence se voit immédiatement dans la manière de concevoir les priorités. Le BCM cherche la reprise après sinistre. La résilience cherche la continuité de service sous contrainte. Le résultat n'est pas le même pour les équipes métier, ni pour les clients.
| Critère | BCM Traditionnel | Résilience Opérationnelle |
|---|---|---|
| Finalité | Reprendre après interruption | Continuer à délivrer un service acceptable pendant l'incident |
| Point de départ | Scénario de sinistre | Service métier critique et impact client |
| Horizon | Reprise ponctuelle | Capacité continue d'absorption et d'adaptation |
| Pilotage | Souvent centré IT | Transverse métier, IT, risques, conformité, service client |
| Relation aux tiers | Sujet annexe | Composant central de l'exposition au risque |
| Mesure de succès | Retour à la normale | Maintien de la valeur, de la confiance et apprentissage utile |
Ce tableau change aussi les arbitrages budgétaires. Investir dans la résilience ne signifie pas seulement financer de la redondance. Cela peut vouloir dire revoir un parcours client, simplifier une chaîne de validation, documenter un mode dégradé ou équiper le front avec des agents capables d'informer correctement.
Les piliers qui tiennent dans la durée
Dans la pratique, j'observe cinq piliers qui distinguent les programmes sérieux des dispositifs purement déclaratifs.
- Prévention. Cartographier les dépendances réelles, pas uniquement les applications officielles.
- Réponse. Décider vite, avec une chaîne d'escalade courte et comprise de tous.
- Récupération. Revenir à un niveau de service maîtrisé, pas seulement rallumer l'outil.
- Adaptation. Ajuster les processus si la perturbation dure.
- Apprentissage. Transformer le post-mortem en correction durable.
Une organisation résiliente n'attend pas le retour complet à la normale pour reprendre la main. Elle sait opérer dans l'inconfort, avec des priorités clarifiées.
Ce qui ne fonctionne pas, en revanche, est très constant. Les plans figés dans un dossier partagé ne servent pas assez. Les exercices trop théoriques donnent une illusion de préparation. Les dépendances critiques non documentées reviennent toujours au pire moment. Et les approches purement NLP, limitées à des intentions statiques, montrent vite leurs limites quand il faut gérer des situations mouvantes. Aujourd'hui, on privilégie les LLM over NLP, parce qu'ils gèrent mieux la variabilité du langage, du contexte et des demandes en crise.
Comprendre le cadre réglementaire DORA et les exigences sectorielles
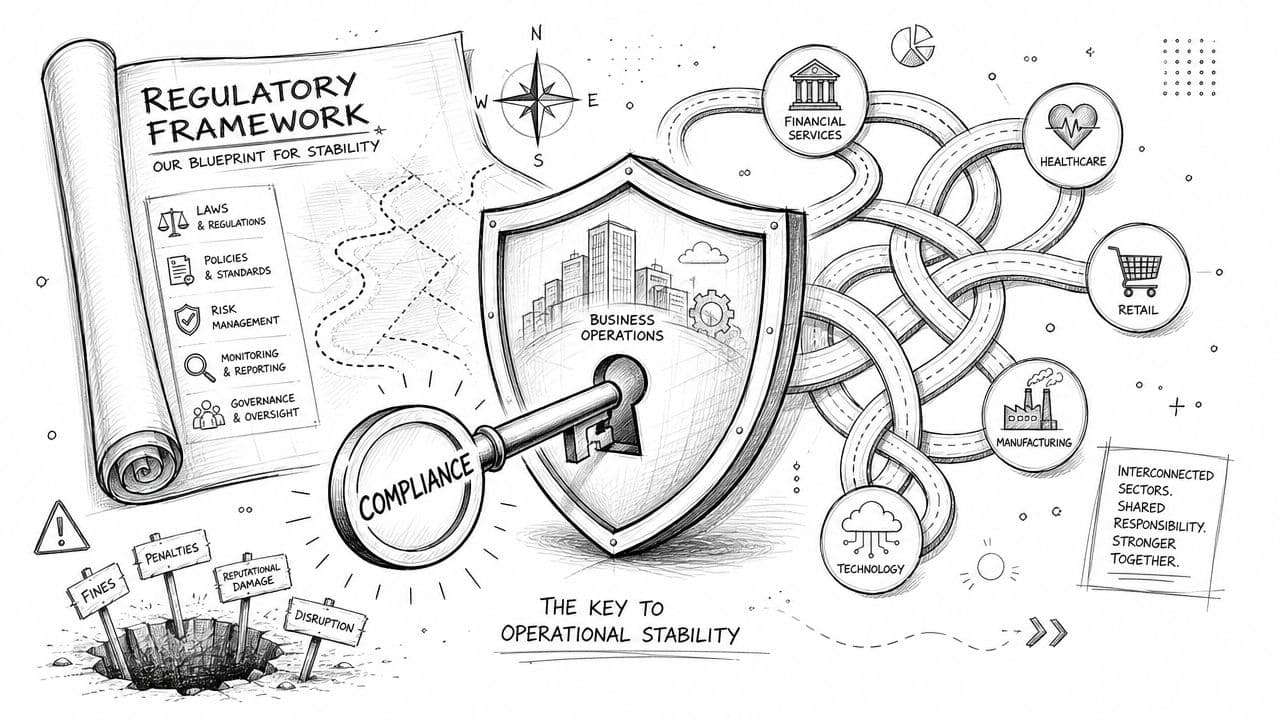
DORA a eu un mérite immédiat. Il a obligé beaucoup d'organisations à sortir d'une vision compartimentée de la continuité. La résilience n'est plus traitée comme une combinaison de sécurité, de PRA et de conformité documentaire. Elle devient un cadre de pilotage de services critiques.
Ce que DORA change concrètement
Sans entrer dans une lecture juridique article par article, DORA pousse les acteurs financiers et leur écosystème à structurer cinq chantiers très concrets :
- La gestion des risques TIC. Identifier les fonctions critiques, cartographier les actifs et maintenir une vision à jour des dépendances.
- La gestion des incidents. Détecter, qualifier, documenter et notifier avec une discipline plus forte.
- Les tests de résilience. Faire autre chose que des tests de restauration théoriques.
- Le pilotage des tiers. Considérer les fournisseurs comme une extension du risque opérationnel.
- Le partage d'informations. Faire circuler les signaux faibles et les retours utiles.
Le point important n'est pas seulement la liste. C'est la responsabilité de gouvernance. La direction ne peut plus se contenter de déléguer le sujet à l'IT ou au RSSI. Elle doit arbitrer, prioriser et suivre les expositions qui menacent les services essentiels. Pour les équipes de relation client, cela change aussi la donne. La communication sortante, la qualité des réponses et la cohérence de l'information deviennent des éléments de résilience, pas seulement de support. Dans ce cadre, une base de connaissance IA pour le service client peut jouer un rôle structurant si elle aligne les réponses sur des sources validées.
Pourquoi le sujet dépasse la finance
Ce serait une erreur de considérer DORA comme un sujet réservé aux banques, assurances et fintechs. Le mouvement réglementaire va plus loin. Santé, services publics, infrastructures critiques et organisations fortement dépendantes au numérique convergent vers les mêmes exigences de fond. Il faut prouver qu'on connaît ses dépendances, qu'on sait tester, qu'on gère ses fournisseurs et qu'on maintient des capacités de fonctionnement même sous stress.
Le bon réflexe consiste à voir la conformité comme un cahier des charges de qualité opérationnelle. Pas comme une punition. Les entreprises qui l'abordent ainsi prennent de meilleures décisions. Elles standardisent leur documentation, alignent métiers et IT, puis rendent les scénarios de crise plus actionnables. Celles qui restent dans une logique de production de preuves pour l'audit passent souvent à côté du vrai sujet. Elles documentent beaucoup, mais réduisent peu leur fragilité réelle.
Mettre en place la gouvernance et les processus clés
La résilience échoue rarement faute de technologies. Elle échoue parce que personne n'a clairement défini qui tranche, quels services passent en priorité, quels fournisseurs sont réellement critiques et à quel moment on bascule en mode dégradé.
Identifier ce qui ne peut pas tomber
La première étape n'est pas de lister tous les risques. C'est d'identifier les services essentiels à maintenir. Dans une banque, ce peut être la consultation de compte, le blocage carte ou l'information sur un incident. Dans un e-commerce, ce sera souvent le paiement, le suivi de commande et la gestion des retours. Dans la santé, la criticité se situe souvent dans l'accès fiable à l'information et la fluidité des réponses.
Ensuite, il faut remonter la chaîne de dépendance réelle. Application, API, prestataire, équipe interne, procédure manuelle de secours, canal de contact. C'est ici que beaucoup d'organisations découvrent leur angle mort. Le service paraît solide sur le papier, mais dépend d'un seul fournisseur, d'un validation humaine non remplaçable ou d'un back-office trop peu outillé. Pour absorber ces points de fragilité, certaines équipes gagnent à outiller les opérations administratives répétitives avec des Agents IA pour le back-office, là où un simple script ou une logique RPA se casse dès qu'un cas sort du cadre.
Point d'attention: un fournisseur n'est pas “non critique” parce qu'il ne facture pas beaucoup. Il peut être critique s'il bloque une information, un flux ou une décision indispensable.
Installer des rituels utiles
La gouvernance sérieuse repose sur des rituels courts et réguliers. Pas sur un grand comité semestriel qui découvre les problèmes après coup.
Je recommande en général quatre mécanismes simples :
- Une revue des services critiques. Les métiers, l'IT, le risque et le service client doivent y parler le même langage.
- Un registre vivant des tiers sensibles. Il doit inclure les dépendances techniques, contractuelles et opérationnelles.
- Des exercices de crise réalistes. Avec rupture de communication, indisponibilité partielle et surcharge du support.
- Un retour d'expérience exploitable. Chaque incident doit déboucher sur une décision de simplification, de sécurisation ou de réallocation.
Ce qui marche le mieux, ce sont les tests qui impliquent les personnes qui opèrent vraiment le service. Ce qui marche mal, ce sont les scénarios trop propres, trop techniques ou trop éloignés du client final. Un bon exercice doit mettre l'organisation face à des dilemmes concrets. Qui parle au client. Quelle information est validée. Quelle opération reste possible. Quel canal absorbe la demande.
Le rôle des technologies et des Agents IA dans la résilience
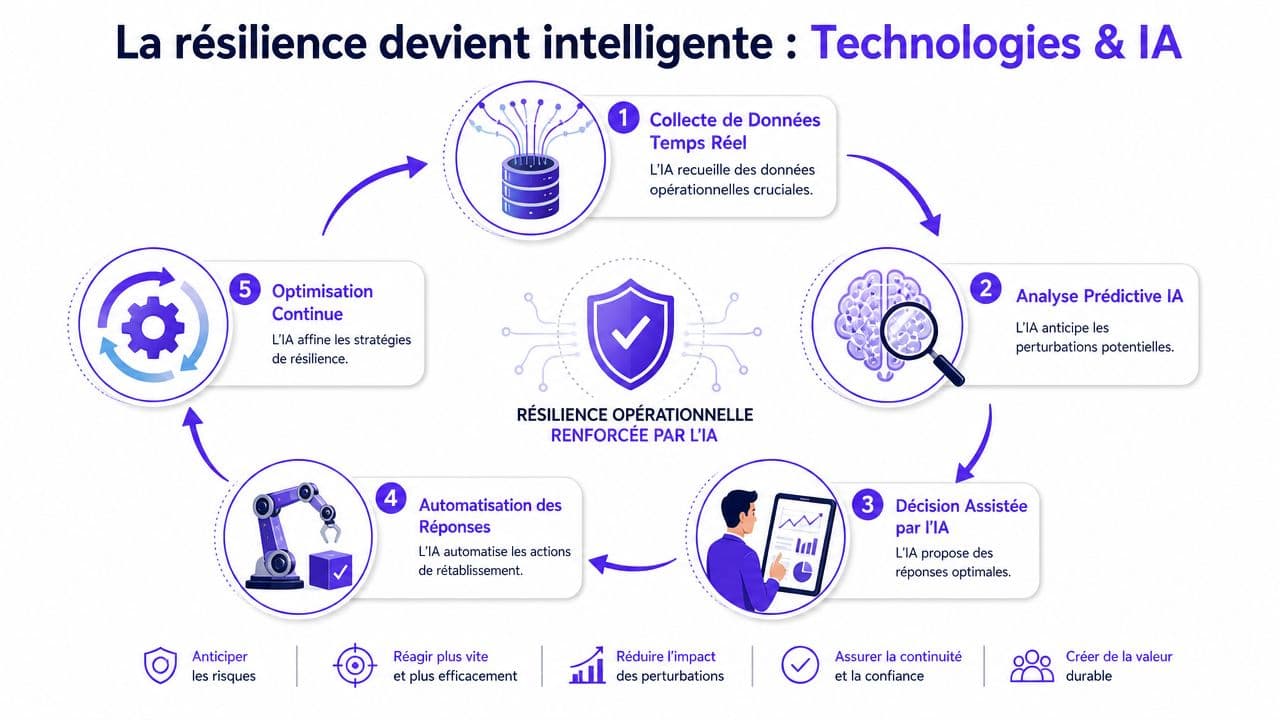
La résilience technologique a longtemps été dominée par une logique d'infrastructure. Redondance, sauvegarde, PRA, supervision. Tout cela reste indispensable. Mais ce n'est plus suffisant. Une entreprise peut avoir une architecture solide et pourtant échouer sur le point décisif, maintenir une expérience client cohérente quand le système est sous tension.
Pourquoi l'infrastructure seule ne suffit plus
Pendant un incident, le premier goulet d'étranglement n'est pas toujours la plateforme. C'est souvent l'interaction. Les clients appellent, écrivent, relancent, demandent une explication, veulent savoir quoi faire, si leur opération est bloquée ou si une action urgente est nécessaire. Si l'entreprise ne répond pas vite, l'incident technique devient une crise de confiance.
C'est là que les Agents IA changent la donne. Pas les anciens chatbots figés, construits comme des arbres de décision FAQ. Pas non plus une logique RPA pure, très utile pour des séquences stables mais trop rigide dans des contextes conversationnels variés. Ici, il faut des agents capables de comprendre la demande, de se connecter au SI, d'utiliser une base documentaire gouvernée, de qualifier l'urgence et d'escalader proprement.
Le point méthodologique est important. On utilise LLM over NLP, et AI Agents over RPA pour les scénarios de résilience côté interaction. Pourquoi ? Parce qu'un incident réel produit des formulations imprévisibles, des questions incomplètes, des émotions, des changements de consigne et des besoins de personnalisation. Les modèles LLM, encadrés par des sources et des règles, gèrent mieux cette complexité. Les Agents IA, eux, permettent d'orchestrer action, réponse et transfert.
Autre point souvent sous-estimé, la résilience commence par un socle d'infrastructure sain. Si l'hébergement ou les couches applicatives sont fragiles, la meilleure stratégie conversationnelle compensera mal. Pour les équipes qui veulent sécuriser cette base, s'appuyer sur un hébergement web fiable fait partie des décisions structurantes, au même titre que la supervision ou les mécanismes de bascule.
Un cas d'usage concret côté service client
Prenons un scénario fréquent dans la banque ou l'assurance. Une indisponibilité partielle touche un parcours digital. Les clients ne savent pas si l'opération est perdue, retardée ou simplement visible avec décalage. Le centre de contact sature très vite.
Dans ce cas, un agent conversationnel moderne peut jouer plusieurs rôles en parallèle :
- Informer de manière cohérente. Même message, mêmes consignes, même niveau de prudence sur tous les canaux.
- Absorber les demandes simples. État de situation, prochaines étapes, canaux alternatifs, gestes immédiats.
- Qualifier les urgences. Distinguer l'inconfort du cas critique qui doit être repris par un humain.
- Réaliser certaines actions de base. Selon les intégrations disponibles, sans surcharger les équipes.
Cette approche produit un effet très concret sur la continuité de service. Les entreprises qui utilisent des Agents IA pour gérer les interactions client lors de pics d'activité ou d'incidents signalent une capacité de traitement des demandes 80% supérieure sans augmentation des effectifs, avec maintien du score de satisfaction client ou CSAT (résultats observés sur les Agents IA). Ce n'est pas un argument théorique. C'est exactement ce qu'on attend d'un dispositif de résilience opérationnelle bien conçu. Maintenir le service sans effondrer les équipes ni dégrader l'expérience.
Dans ce domaine, la bonne décision n'est généralement pas de déployer “un chatbot”. C'est de définir un périmètre de continuité, d'y connecter un agent IA opérationnel pour les interactions critiques, puis de tester ce dispositif en conditions dégradées. C'est aussi la raison pour laquelle les programmes les plus résilients parlent désormais d'agents et non d'automates isolés.
Votre feuille de route pour une résilience opérationnelle efficace
La pire approche consiste à vouloir tout traiter en même temps. La bonne consiste à partir d'un service critique, d'un scénario crédible et d'une chaîne de dépendance vérifiable. Une résilience opérationnelle efficace se construit par priorités nettes, avec des quick wins visibles et des mécanismes d'amélioration continue.

Commencer petit, mais sur un périmètre critique
Le bon point d'entrée est rarement un programme global. C'est un service où l'impact client est immédiat et où les dépendances sont suffisamment lisibles pour agir vite. Par exemple, le traitement des appels lors d'un incident, la communication proactive sur un parcours indisponible, ou le maintien d'un front de support pendant une panne d'outil interne.
Je conseille souvent une séquence simple :
- Choisir un service critique avec sponsor métier clair.
- Définir les impacts tolérables en mode dégradé.
- Cartographier les dépendances internes et externes.
- Tester un scénario de rupture plausible.
- Corriger un point de faiblesse visible avant d'élargir.
Quand une organisation bloque sur la stratégie globale, il faut revenir à une question plus opérationnelle. Quel service devez-vous continuer à rendre demain matin, même si une brique importante tombe cette nuit ?
Checklist des quick wins prioritaires
Voici les actions qui donnent le plus de traction au démarrage.
- Cartographier un parcours client critique. Pas tout le SI. Un parcours précis, avec applications, équipes, fournisseurs et canaux.
- Nommer un responsable de continuité par service essentiel. Sans propriétaire clair, les arbitrages restent trop lents.
- Lister les fournisseurs qui peuvent casser le service. Inclure ceux qui gèrent la donnée, l'hébergement, la téléphonie, les intégrations ou la diffusion d'information.
- Documenter un mode dégradé réaliste. Que peut-on encore faire manuellement, partiellement, ou via un canal alternatif.
- Tester la communication client de crise. Beaucoup d'entreprises découvrent qu'elles n'ont pas de message prêt, ni de circuit de validation fluide.
- Lancer un PoC sur un périmètre de contact tendu. Un callbot pour absorber un pic d'appels sur incident est souvent un excellent point de départ si le volume et la répétitivité des demandes sont élevés.
- Mesurer les apprentissages après exercice. Le test ne vaut que s'il produit une simplification, une décision ou une correction.
Ce qui compte n'est pas la perfection documentaire. C'est la capacité à créer une boucle courte entre exposition, test, correction et montée en puissance. Les entreprises qui progressent vite sont celles qui rendent la résilience visible dans les opérations quotidiennes. Pas seulement dans les rapports.
Webotit.ai aide les entreprises à transformer la résilience opérationnelle en capacité concrète de continuité côté relation client et opérations. Si vous voulez cadrer un cas d'usage, prioriser les quick wins ou évaluer le rôle des Agents IA dans vos scénarios de crise, découvrez la plateforme sur Webotit.ai.